
Unit Testing Agents
Often times, agents will fail at specific workflows. To improve the agent's performance, we need to isolate the task and experiment with different configurations to understand the impact. This offline agent evaluation is similar to unit testing with traditional software development.
We recommend the Patronus experiments framework for creating unit tests for agentic systems. Let's walk through an example of evaluating an agent that generates a tool call.
Task Definition
The first step in unit testing an agent is determining which task or sub-process you want to evaluate. Examples of sub-processes in agents:
- Retrieval module returning documents
- Tool call responses
- LLM generations
Each of these sub-processes can fail for different reasons. Our experiments framework consists of several core concepts. In AI workflows:
- Task: A unit of work in your AI system. We recommend testing challenging components and not trivial tasks. For example, a task can assess whether the agent called the right tool in your ecosystem.
- Dataset: Inputs to your agent task. This can include user inputs, mocked API responses, system prompts. The key is to preserve state with your production environment to run a fair eval for the specific task you are assessing.
- Evaluator: Evaluators score the agent responses on whether they are good or bad. The specific evaluator is task specific. In many cases in offline development, the evaluator may simply verify if the agent output is similar or not to the gold (human annotated) answer.
Unit Testing Agents
Let's go back to our definition of a crewAI agent in Agent Observability. In a production system, the API tool call is just one of many tools the agent has access to.
import json
from tqdm import tqdm
from typing import ClassVar, Optional
from crewai_tools import BaseTool
from openai import OpenAI
class ReadFileTool(BaseTool):
def _run(self, file_path: str) -> str:
...
class ReadJSONLTool(BaseTool):
def _run(self, file_path: str) -> list:
...
class ReadJSONTool(BaseTool):
def _run(self, file_path: str) -> dict:
...
class APICallTool(BaseTool):
def _run(self, system_prompt: str=None, prompt: str=None) -> str:
...
Some of these tools are simple I/O operations, and less likely to result in failures. Suppose we want to unit test the APICallTool due to its non-deterministic responses. The next step is to construct a Dataset to evaluate our agent performing this task. The Dataset consists of a set of inputs to the task, and can also contain expected responses. We will create a CSV file containing questions to the LLM API and expected responses.
input,gold_answer
"What historical event did President Biden reference at the beginning of his 2024 State of the Union address?","Franklin Roosevelt's address to Congress in 1941"
We can now create an evaluation script using the Experiments SDK where we evaluate the agent's tool call response. Note that this script uses asynchronous calls, though our CrewAI agent example uses synchronous operations. This is to illustrate how to use Patronus in async contexts.
from patronus import Client, task, evaluator, Row, TaskResult, read_csv
from tool import APICallTool
from uuid import UUID
import csv
import asyncio
client = Client()
@task
async def my_task(row: Row):
evaluated_model_input = row.evaluated_model_input
evaluated_model_system_prompt = "You are a helpful assistant. Answer to the best of your ability."
tool = APICallTool()._run(
system_prompt=evaluated_model_system_prompt,
prompt=evaluated_model_input
)
@evaluator
def exact_match(row: Row, task_result: TaskResult):
return task_result.evaluated_model_output == row.evaluated_model_gold_answer
async def run_experiment():
dataset = read_csv(
"sample_dataset.csv",
evaluated_model_input_field="input",
evaluated_model_output_field="gold_answer",
)
await client.experiment(
"Tutorial Project",
dataset=dataset,
task=my_task,
evaluators=[exact_match],
tags={"experiment": "example_experiment"}, # You can include arbitrary tags
experiment_name="Agent Experiment",
max_concurrency=3
)
if __name__ == "__main__":
asyncio.run(run_experiment())
In the above,
my_taskcalls theAPICallToolto execute an API call with a given system and user promptexact_matchevaluator checks whether the output of the task matches the expected responserun_experimentloads a sample datasettagslog arbitrary experiment associated metadata, which can be used for filtering
You can manage and compare experiment performance in Experiments. Each experiment run shows you aggregate metrics including accuracy and statistics over the test dataset.
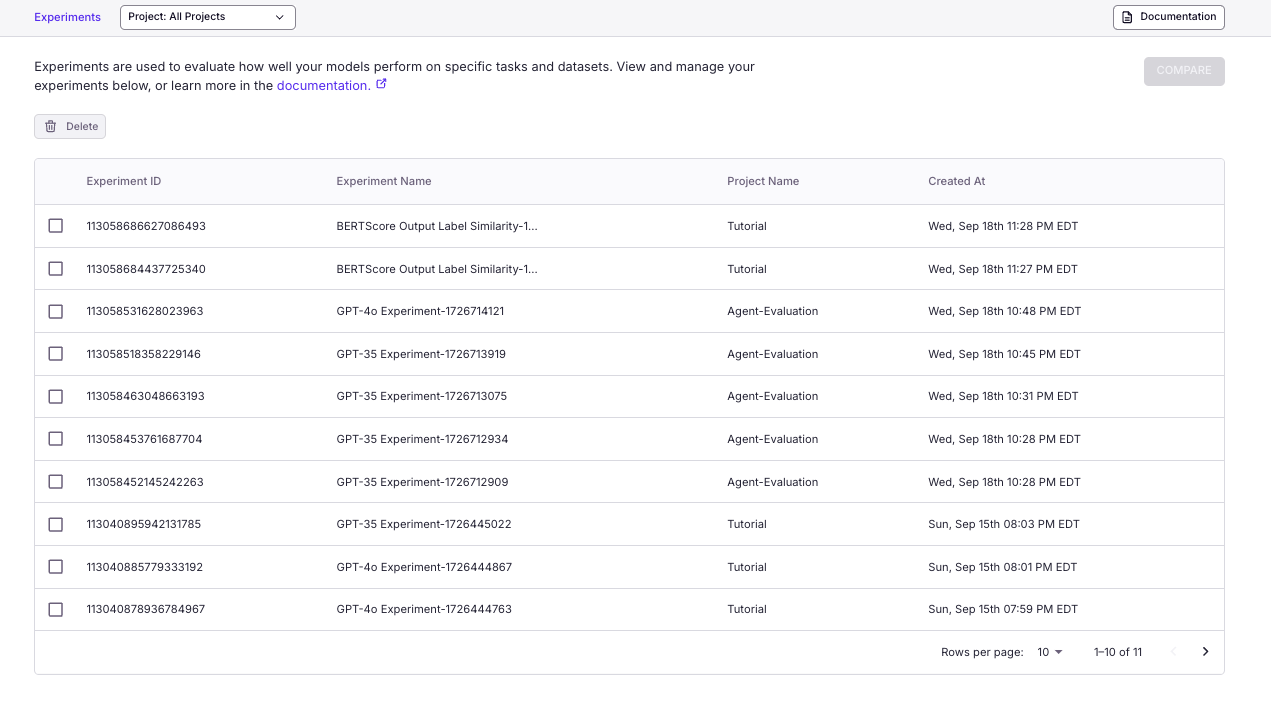
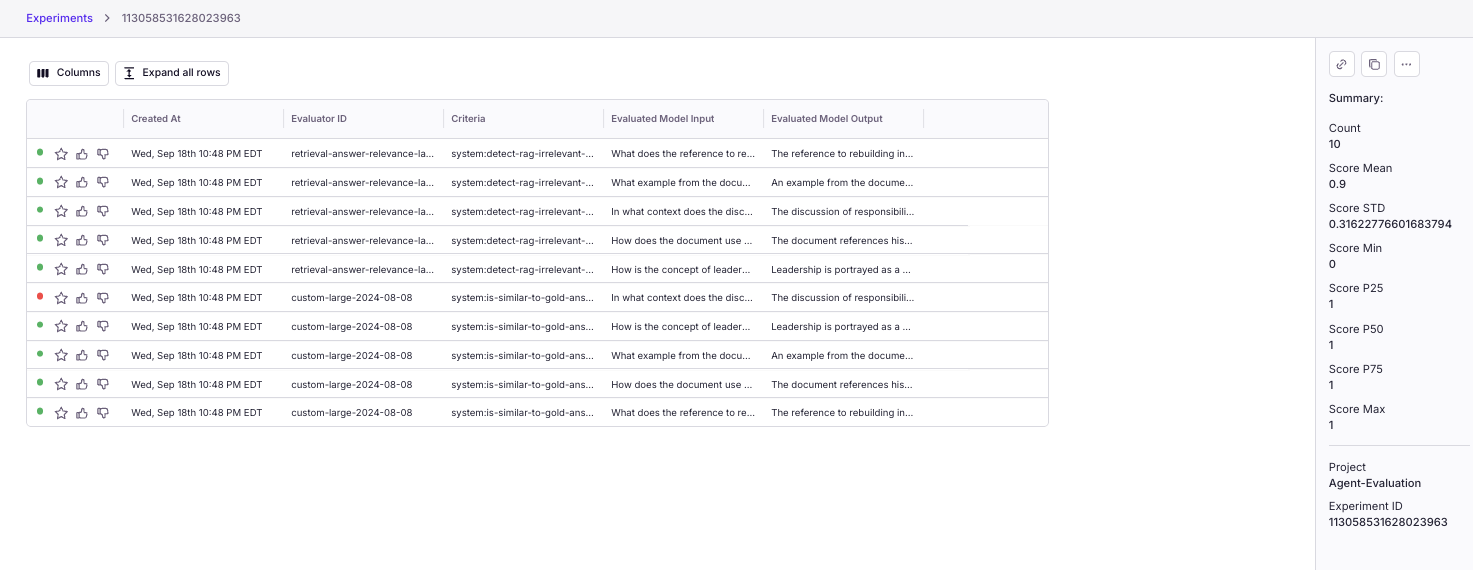
Can you optimize prompts to fix your agent? Read more in Experiments and Comparisons.
Updated 19 days ago