
Evaluating RAG Agents
Here is how you can evaluate a RAG agent with the Patronus python SDK! In this tutorial we'll walk you through how to evaluate a RAG agent that answers questions about Biden's March 2024 State of the Union address, and uses LlamaIndex and GPT-3.5.
1. Create Dataset
First, let's create a dataset with questions about this document.
dataset = [
{
"evaluated_model_input": "What historical event did President Biden reference at the beginning of his 2024 State of the Union address?",
"evaluated_model_gold_answer": "President Biden referenced Franklin Roosevelt's address to Congress in 1941 during World War II, highlighting how Roosevelt warned the nation about the assault on freedom and democracy."
},
{
"evaluated_model_input": "How did President Biden describe the current threat to democracy in his 2024 State of the Union address?",
"evaluated_model_gold_answer": "President Biden described the threat to democracy as unprecedented since the Civil War, with attacks on freedom both at home and abroad, including Russia's invasion of Ukraine and domestic political violence."
},
{
"evaluated_model_input": "What stance did President Biden take on NATO in his 2024 State of the Union address?",
"evaluated_model_gold_answer": "President Biden emphasized the importance of NATO, stating that the alliance is stronger than ever with the inclusion of Finland and Sweden, and reaffirmed the need to stand against Russia's aggression."
},
{
"evaluated_model_input": "What is President Biden's message regarding assistance to Ukraine?",
"evaluated_model_gold_answer": "President Biden urged Congress to continue providing military aid to Ukraine, arguing that Ukraine can stop Putin if supported with the necessary weapons, and stressing that American soldiers are not involved in the conflict."
},
{
"evaluated_model_input": "What did President Biden propose regarding the cost of insulin?",
"evaluated_model_gold_answer": "President Biden proposed capping the cost of insulin at $35 a month for all Americans, building on a law that already capped it for seniors on Medicare."
}
]
2. Parse and Load Document
We will build a simple vector store with some example State of the Union addresses. First, we will download Biden's SOTU speech from March 8 2024: https://www.congress.gov/118/meeting/house/116942/documents/HHRG-118-JU00-20240312-SD001.pdf
$ mkdir docs
$ wget --user-agent "Mozilla" "https://www.congress.gov/118/meeting/house/116942/documents/HHRG-118-JU00-20240312-SD001.pdf" -O "data/SOTU.pdf"
We will parse and load these documents into a vector store.
from llama_index.core import SimpleDirectoryReader
from llama_index.core import VectorStoreIndex
# Metadata extraction
def get_metadata(file_path):
file_type = file_path.split(".")[-1]
file_name = file_path.split(".")[0]
return {
"file_name": file_name.split("/")[-1],
"extension": file_type,
"file_path": file_path
}
reader = SimpleDirectoryReader(input_dir="docs", file_metadata=get_metadata)
documents = reader.load_data()
index = VectorStoreIndex.from_documents(documents, show_progress=True)
2. Create LLM Agent
Now let's create a simple RAG agent that receives a user query, queries the DB and passes the context to a LLM. Here we are defining our agent call with the @task decorator to be automatically executed in our experiment.
from llama_index.llms.openai import OpenAI
from patronus import Client, task, TaskResult
model = "gpt-3.5-turbo"
llm = OpenAI(model=model,temperature=0) # You can update and log parameters here
@task
def call_gpt(evaluated_model_input: str) -> TaskResult:
# Replace with your agent query
query_engine = index.as_query_engine(
streaming=True,
similarity_top_k=2,
llm=llm
)
response = query_engine.query(evaluated_model_input)
tags = {}
# log metadata associated with files
doc_metadata = response.source_nodes[0].metadata
tags["file_name"] = doc_metadata["file_name"]
tags["extension"] = doc_metadata["extension"]
tags["file_path"] = doc_metadata["file_path"]
evaluated_model_output = str(response)
return TaskResult(
evaluated_model_output=evaluated_model_output,
evaluated_model_name=model,
evaluated_model_provider="openai",
evaluated_model_selected_model=model,
tags=tags,
)
4. Run Experiment
Let's run an experiment to see the performance of our chatbot! We will use two Patronus evaluators: fuzzy match and answer relevance.
cli = Client()
fuzzy_match = cli.remote_evaluator("custom", "system:check-output-label-match")
rag_answer_relevance = cli.remote_evaluator("retrieval-answer-relevance")
cli.experiment(
"Agent Evaluation",
data=dataset,
task=call_gpt,
evaluators=[fuzzy_match, rag_context_relevance],
tags={"dataset_name": "state-of-the-union-questions", "model": "gpt_35"},
experiment_name="GPT-35 Experiment",
)
You can see the experiment logs in the dashboard:
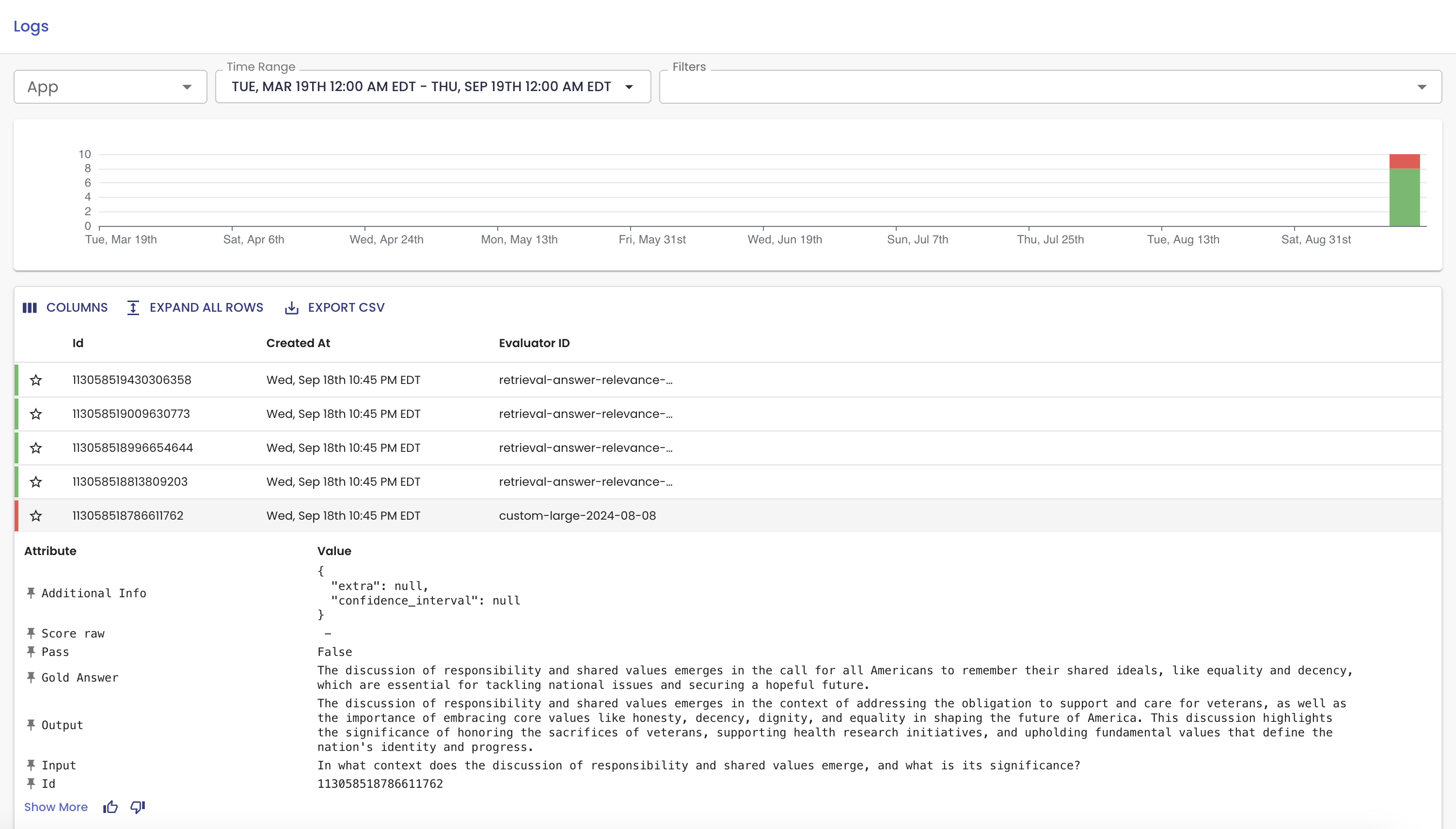
Compare Experiments
Can you improve the accuracy of the agent? Let's re-run the above with GPT-4o. You can see that GPT-4o outperforms GPT-3.5 by 10%!
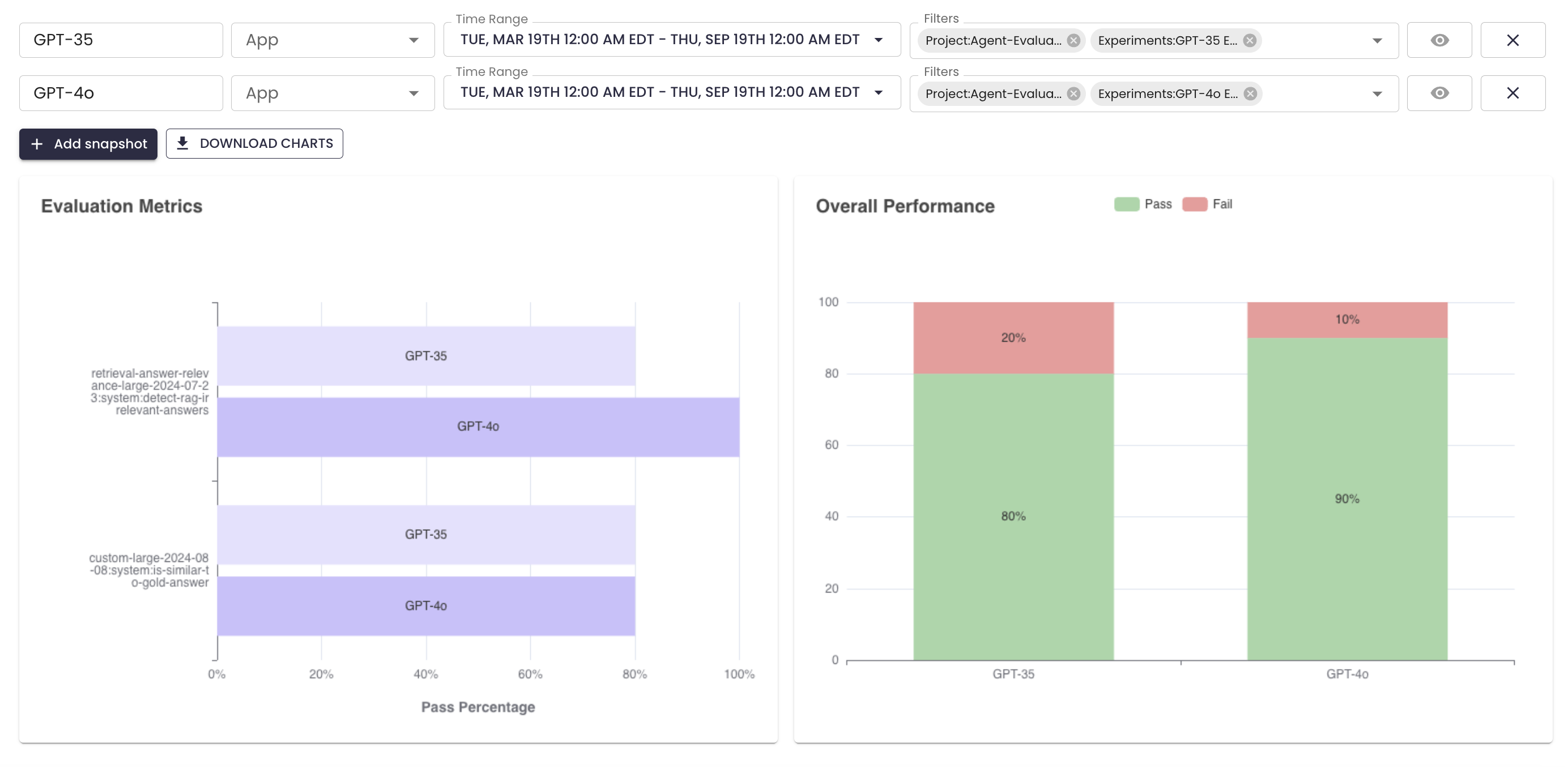
Now you can now build upon this by creating more documents, tweaking the LLM, temperature, prompt and more 🚀
Updated about 19 hours ago