
Quick Start: Log Your First LLM Failure
Estimated Time: 2 minutes
Follow these steps to log your first evaluation result within minutes ⚡
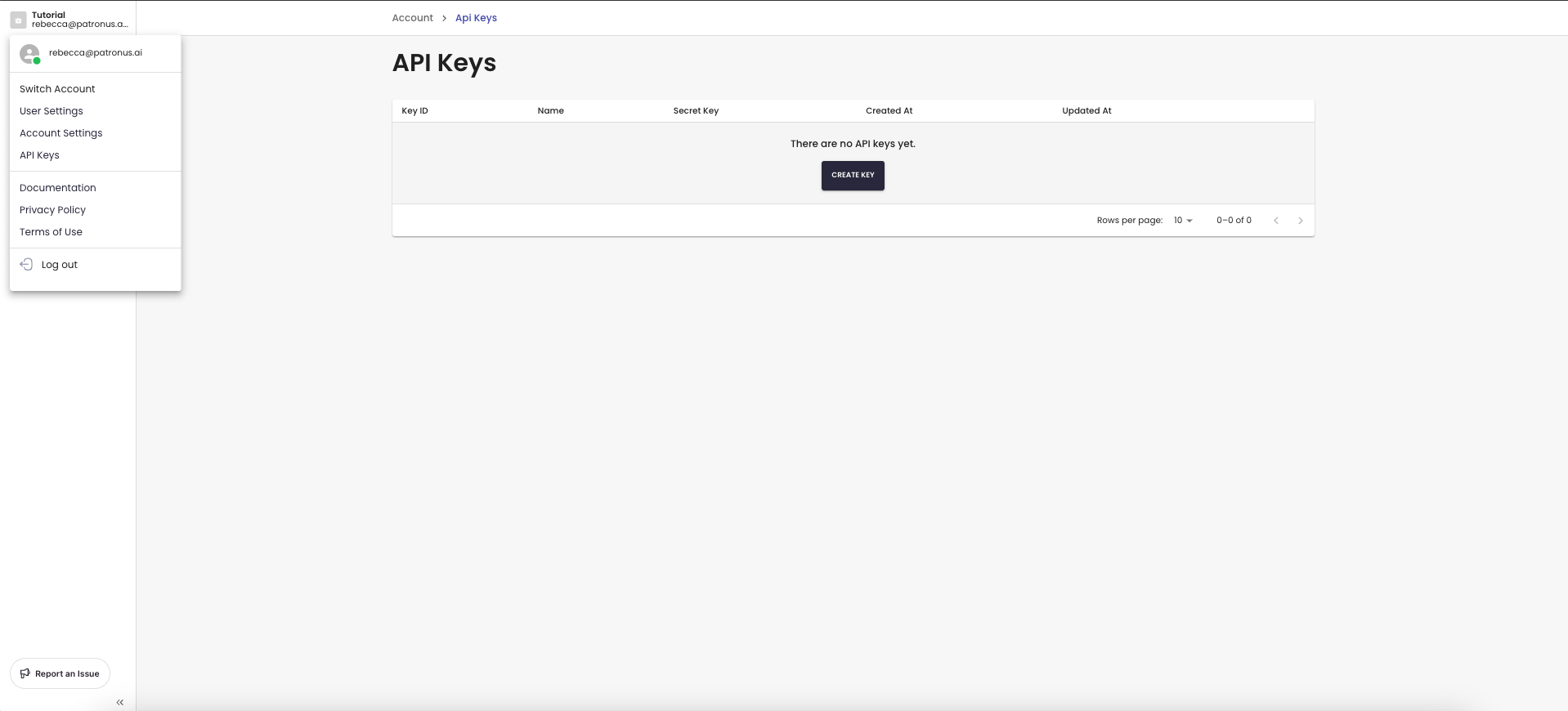
1. Create an API Key 🔑
If you do not have an account yet, sign up for an account at app.patronus.ai.
To create an API key, click on your profile -> API Keys -> Create Key. Make sure you store this securely as you will not be able to view it again.
2. Log an Evaluation 🪵
You can log an evaluation through our Evaluation API. An evaluation consists of the following fields:
- Inputs to your LLM application, eg. "What is Patronus AI?"
- Outputs of your LLM application, eg. "Patronus AI is an LLM evaluation and testing platform."
- Evaluation criteria, eg. hallucination, conciseness, toxicity...and more!
To run your first evaluation, run the following cURL request by replacing YOUR_API_KEY with the API Key you just created.
curl --location 'https://api.patronus.ai/v1/evaluate' \
--header 'X-API-KEY: YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"evaluators": [
{
"evaluator": "retrieval-hallucination-lynx",
"explain_strategy": "always"
}
],
"evaluated_model_input": "Who are you?",
"evaluated_model_output": "My name is Barry.",
"evaluated_model_retrieved_context": ["I am John."],
"tags": {"experiment": "quick_start_tutorial"}
}'
The evaluation result is automatically logged to the Logs dashboard.
3. View Evaluation Logs in UI 📈
Now head to https://app.patronus.ai/logs. You can now view results for your most recent evaluation!
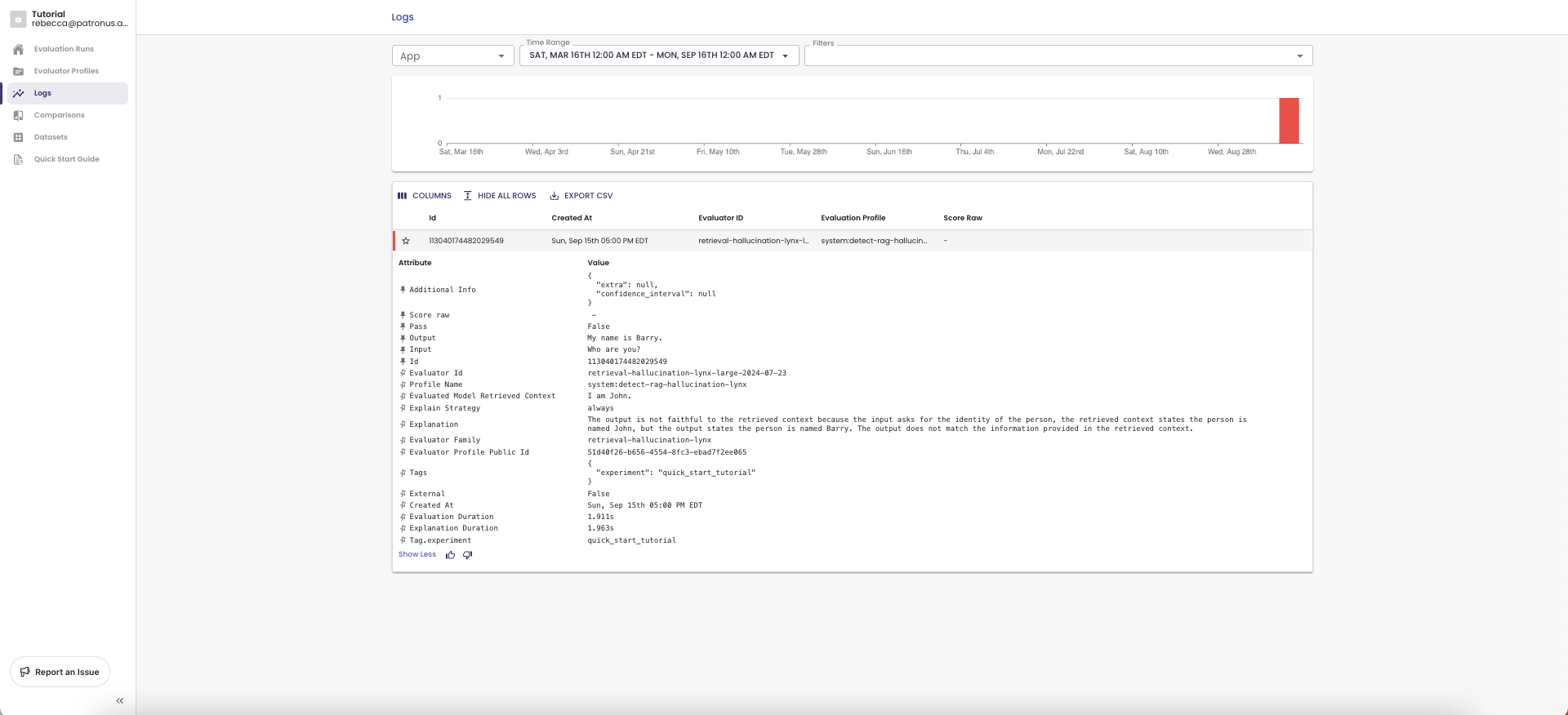
Evaluation Results consist of the following fields:
- Result: PASS/FAIL result for whether the LLM passed or failed the test
- Score: This is a score between 0 and 1 measuring confidence in the result
- Explanation: Natural language explanation for why the result and score was computed
In this case, Lynx scored the evaluation as FAIL because the context states that the name is John, not Barry. We just flagged our first hallucination!
Now that you've logged your first evaluation, you can explore additional API fields, define your own evaluator, or run a batched evaluation experiment.
Updated about 2 hours ago