
Evaluation Runs (Enterprise)
Evaluations Runs is how Patronus supports offline evaluation runs at scale. That means running LLM outputs through an evaluator outside of the real-time use case. You can then visualize results through the Patronus Web App. The easiest way to understand this offering and how to use it on Patronus is to walk through a simple example setup.
Quickstart
To get started with an Evaluation Run in an offline context, you should create a new project on the web app. You can do that on the Dashboard and give it a name.
You can then trigger a new Evaluation Run from there. This will be the offline batch evaluation. It will require a dataset to run through a model, the model you want to test, and the evaluator you want to use for the evaluation. All of these things together will provide the outputs of the run.
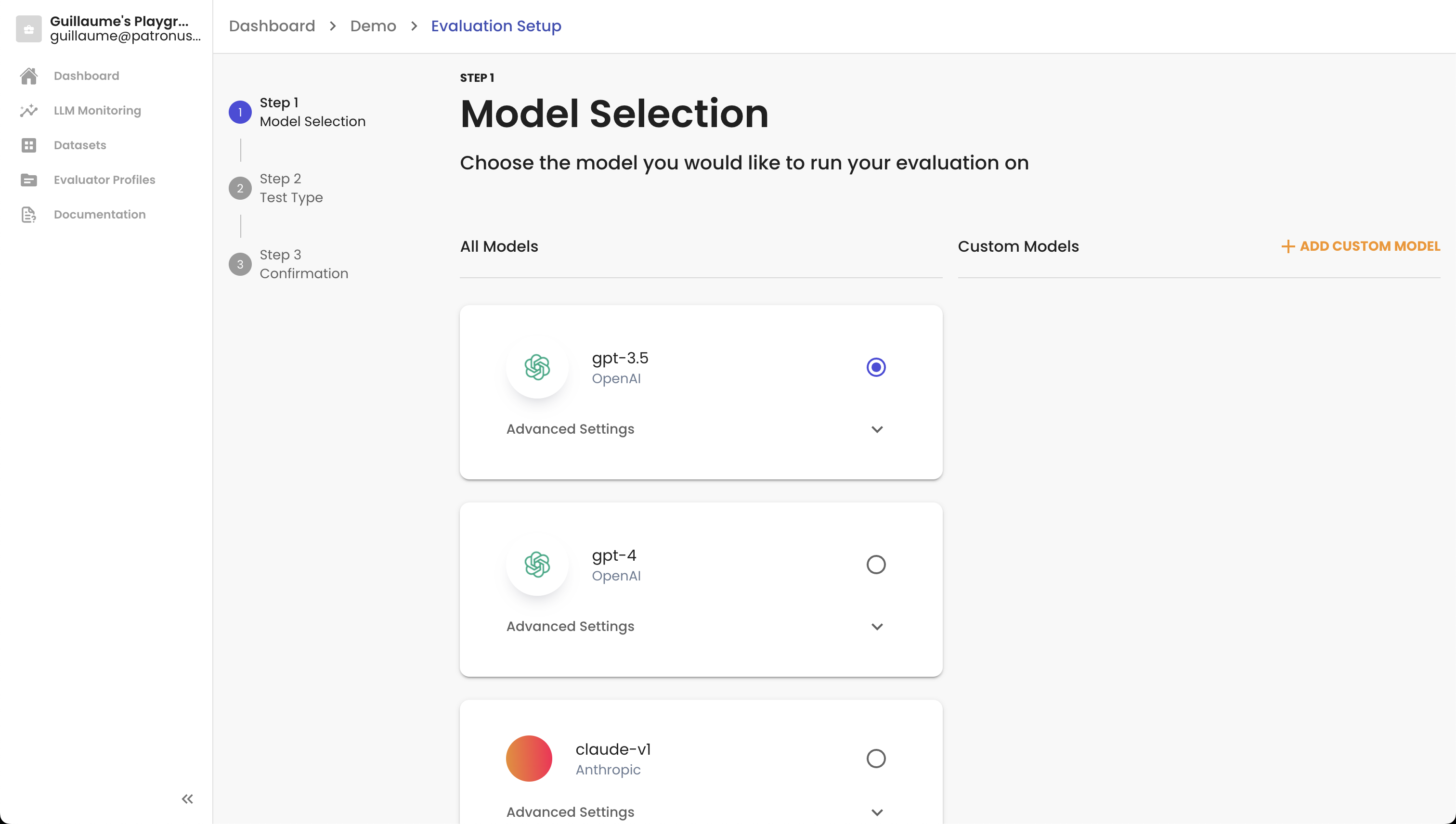
Model Selection
During the first step, you can choose from one of the numerous model integrations we have built right out of the box. These include GPT-4 and GPT-3.5-Turbo, Anthropic Claude models, and Cohere Command models.
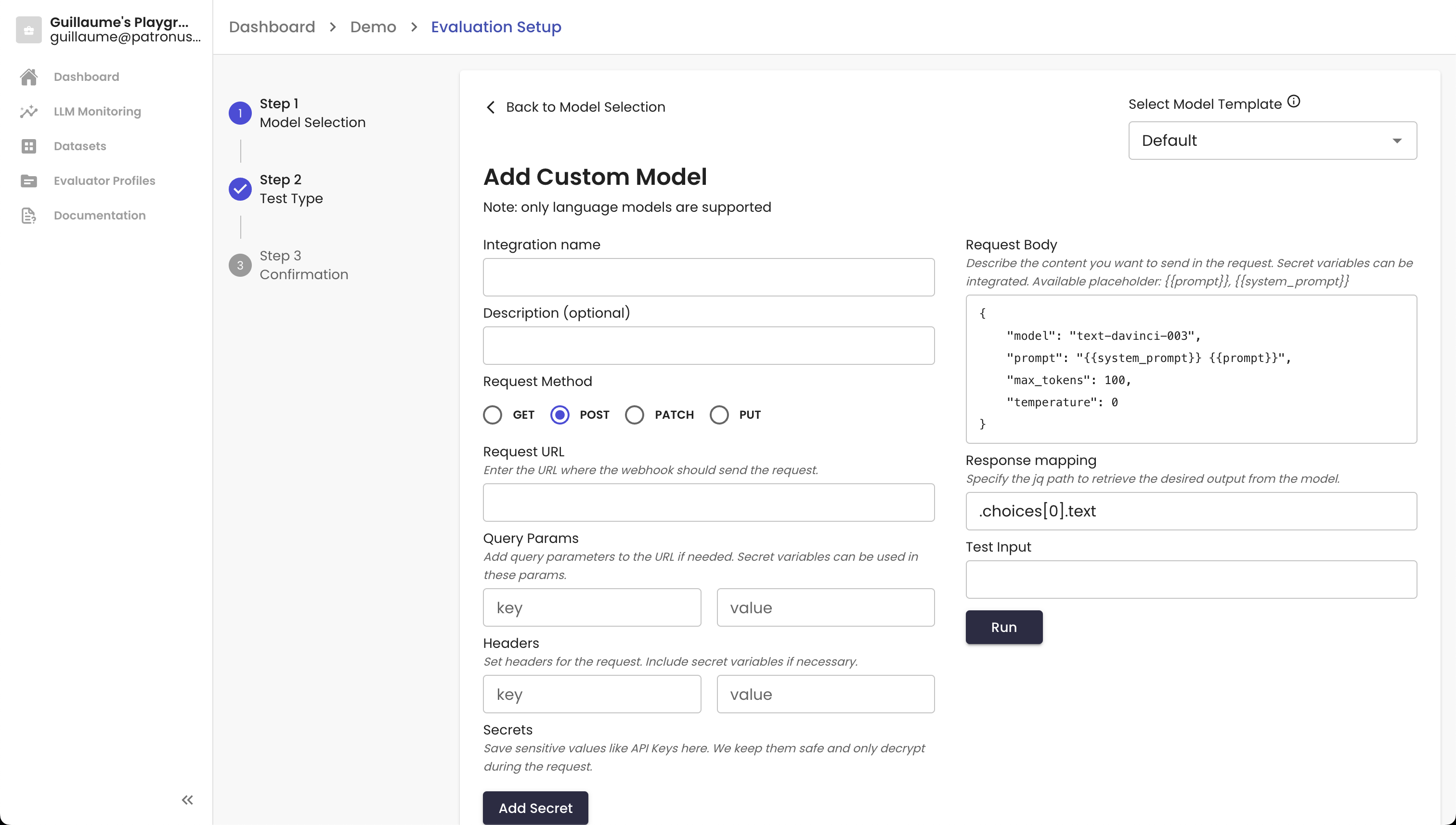
Custom Model Integration
Of course, the pre-integrated models are more helpful for trying out the product than actually evaluating your deployed LLM. We also allow you to integrate with any model that is accessible through a public endpoint. You can Add Custom Model and provide the necessary call details. Then you should be set.
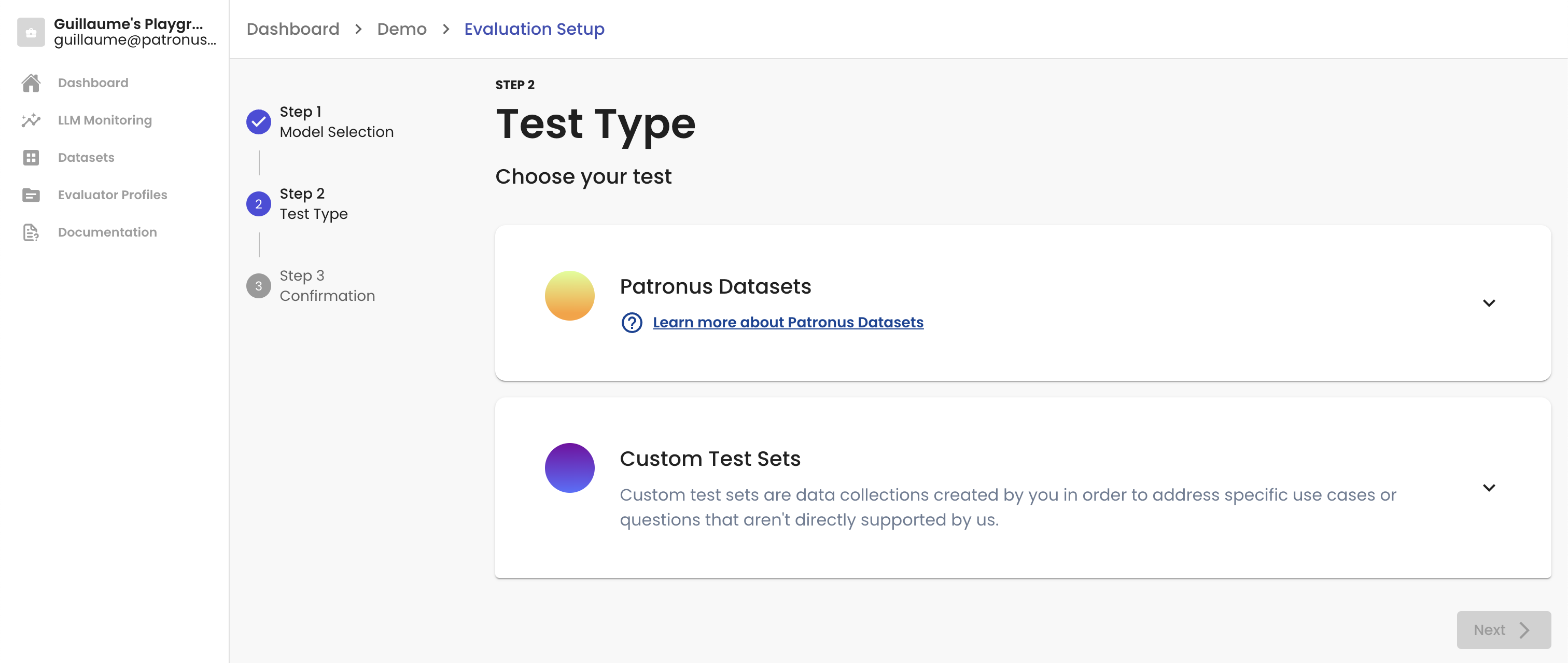
Test Dataset Selection
In the second step, you first need to select the dataset you want to feed through your chosen LLM. We will collect the generated answers before evaluating them. Patronus Datasets are helpful for testing your setup. You can select one of the datasets you uploaded to Patronus earlier.
Evaluation Criteria
The last step before triggering a run is to select an Evaluation Criteria. These can be one of that Patronus manages or a custom one that you created previously and want to create here and now. Once you chose the criteria you would like to use, you can trigger the run and take a look at the results.
Updated about 1 month ago