
Retrieval Evaluators
RAG Evaluation
Retrieval systems are complicated to test, evaluate and debug because there are multiple possible points of failure. We at Patronus use the following helpful framework to disentangle the complexity and identify where issues are coming from.
Retrieval Framework
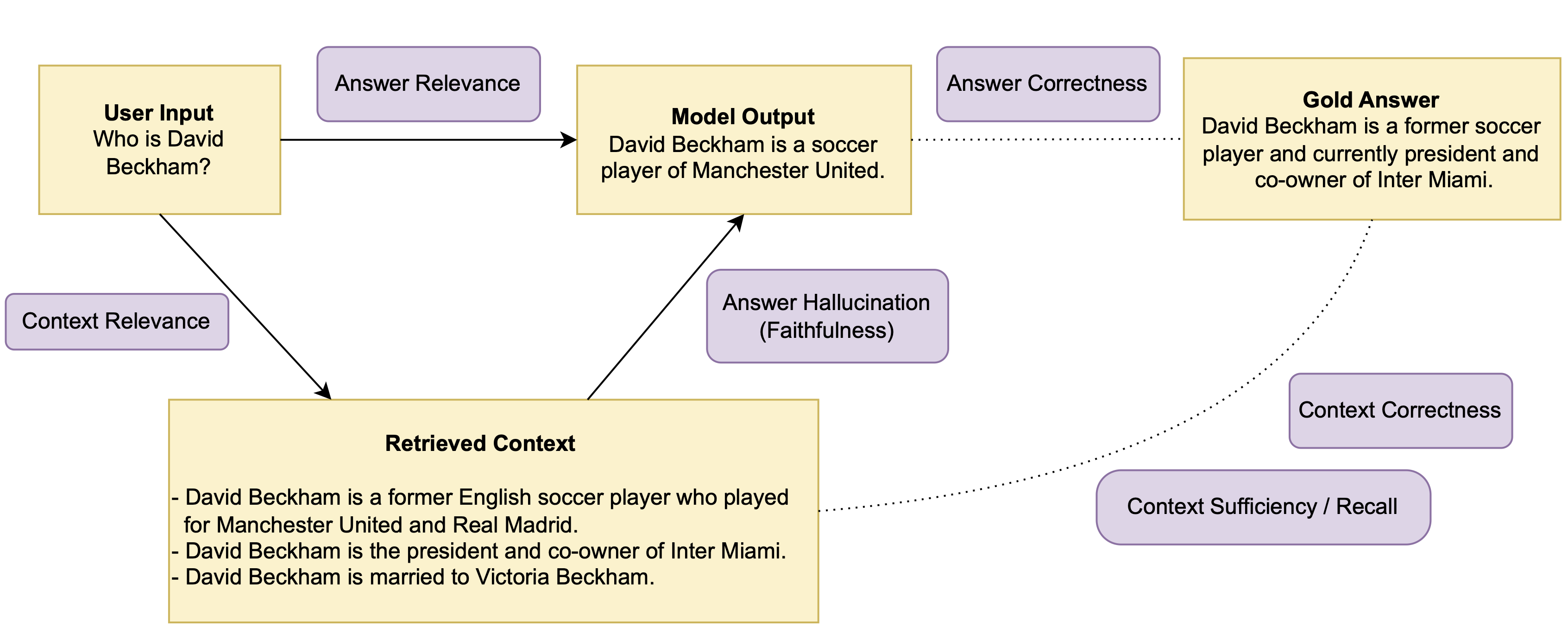
Entities
User Input: User question or statementRetrieved Context: Retrieved context by the RAG system given the user inputModel Output: Answer generated by model given the user input and retrieved contextGold Answer: Reference answer to the user input
Metrics
Answer Relevance: Measures whether the model answer is relevant to the user input.Context Relevance: Measures whether the retrieved context is relevant to the user input.Answer Hallucination (Faithfulness): Measure whether the generated model output is faithful to the retrieved context?
The following metrics require access to a gold/reference answer:
Answer Correctness: Measures whether the model output is consistent with the gold answer.Context Correctness: Measures whether the entities/facts in the retrieved context are in agreement with the entities/facts in the gold answer.Context Sufficiency / Context Recall: Measures whether the retrieved context is sufficient to answer the user input in line with the gold answer.
Patronus Evaluators
Patronus can currently detect the following problems:
- Answer Relevance:
retrieval-answer-relevance - Context Relevance:
retrieval-context-relevance - Context Sufficiency:
retrieval-context-sufficiency - Answer Hallucination (Faithfulness):
retrieval-hallucination
Hallucination Examples
We define a hallucination as a model output that is not faithful to the retrieved context. Here are a few examples from the retrieval_hallucination evaluator family to motivate what this means:
{
"evaluated_model_input": "What is the population of New York from 2022 to 2023?",
"evaluated_model_retrieved_context": [
"The population of New Jersey in 2022 was 10 million people.",
"The population of New Jersey in 2023 was 11 million people."
],
"evaluated_model_output": "The population growth of New York was 1 million people.",
}
- Expected response:
FAIL - Reason: The answer states that the population growth of New York from 2022 to 2023 was 1 million people. However, the retrieved context provides information about the population of New Jersey. Hence, the output does not remain faithful to the retrieved context and is hallucinated!
This hallucination is easy to catch because the retrieved context doesn't mention New York while the output does. But slightly amending the evaluated_model_output in the example results in a hallucination that is much harder to catch:
{
"evaluated_model_input": "What is the population of New York from 2022 to 2023?",
"evaluated_model_retrieved_context": [
"The population of New Jersey in 2022 was 10 million people.",
"The population of New Jersey in 2023 was 11 million people."
],
"evaluated_model_output": "The population growth was 1 million people.",
}
- Expected response:
FAIL
Here is an example where the output is faithful to the context.
{
"evaluated_model_input": "What is the change of population of New York from 2022 to 2023?",
"evaluated_model_retrieved_context": [
"The population of New York in 2022 was 10 million people.",
"The population of New York in 2023 was 11 million people."
],
"evaluated_model_output": "The population growth of New York was 1 million people.",
}
- Expected response:
PASS
Note that in the evaluated_model_retrieved_context array, you can pass different pieces of context as separate items, as seen above.
Updated about 1 month ago