
Uploading Datasets
You can use Patronus to manage your suite of test datasets. Datasets in the UI currently have a limit of 30,000 rows. For datasets that are larger, we recommend loading the datasets locally or with a Pandas DataFrame. We accept .jsonl files that include any of the following string fields:
evaluated_model_input: The prompt provided to your LLM agent or input to a task defined in the experimentation frameworkevaluated_model_output: The output of your LLM agent or taskevaluated_model_retrieved_context: Metadata accessible by your LLM agent or used by the task defined in the experimentation frameworkevaluated_model_gold_answer: The gold answer or expected output
Below is an example JSONL file you might want to upload for a medical help chatbot:
{"evaluated_model_input": "How do I get a better night's sleep?"}
{"evaluated_model_input": "What are common over the counter sleep aids?"}
{"evaluated_model_input": "What are common soccer injuries?"}
{"evaluated_model_input": "Does exercising before sleep help you sleep better?"}
{"evaluated_model_input": "Should I drink boiling water for a sore throat?"}
{"evaluated_model_input": "What does sleep insonmia mean?"}
{"evaluated_model_input": "Where can I find a good doctor?"}
{"evaluated_model_input": "What is the different cycles of sleep?"}
Once you upload the dataset, you'll see it in the Datasets view along with our off-the-shelf datasets.
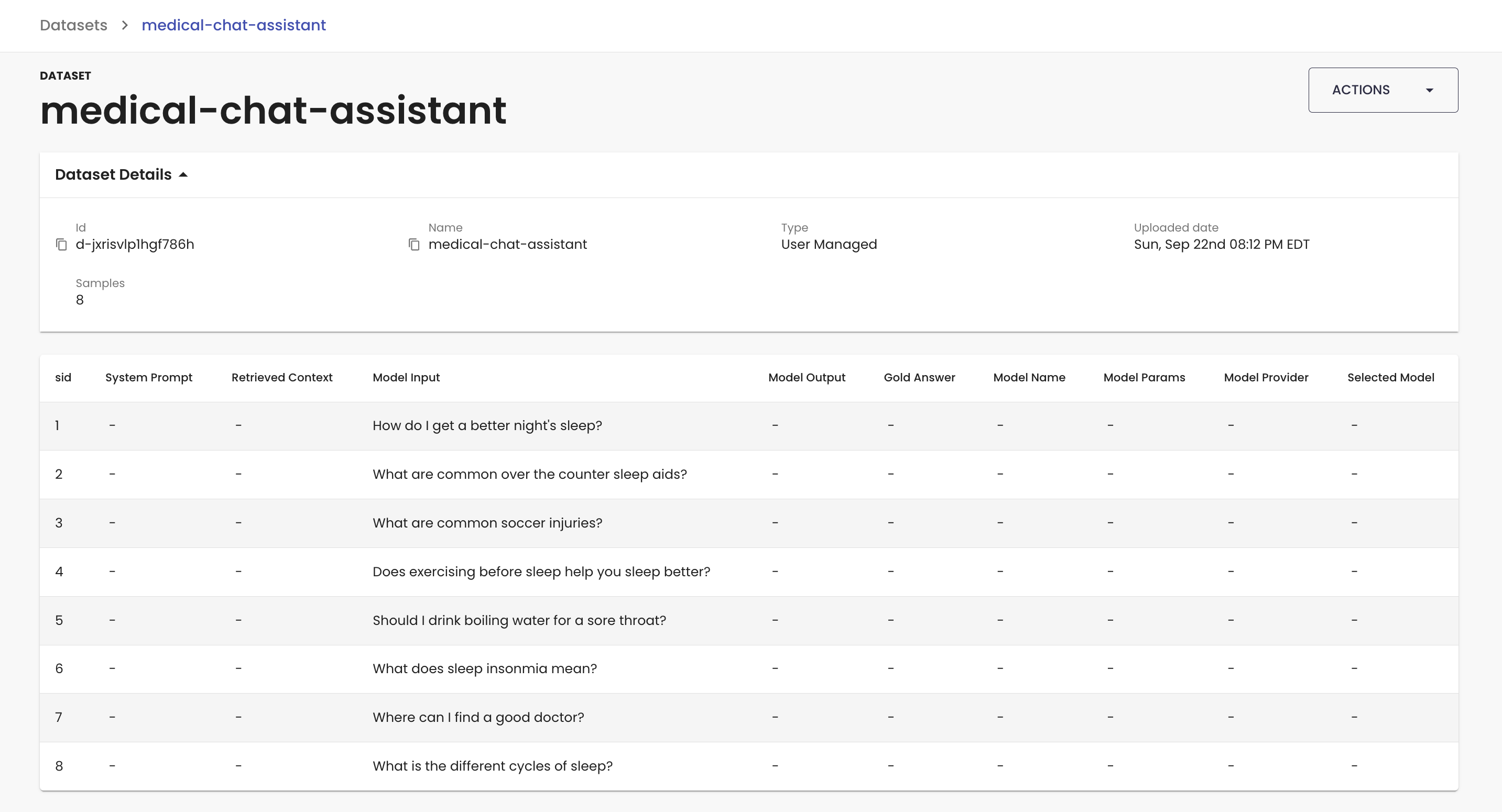
You can now use this dataset in our experiments framework or to run evaluation runs in the platform! To run an experiment with this dataset, reference the dataset using the id field, eg.
medical_chatbot_dataset = client.remote_dataset("d-jxrisvlp1hgf786h")
client.experiment(
"Project Name",
data=medical_chatbot_dataset,
task=task,
evaluators=[evaluator], # Replace with your evaluators
)
See working with datasets for more information.
Updated 7 days ago