
Quick Start: Run an Experiment 🚀
An experiment is an end to end batched evaluation that helps us answer questions such as "Is GPT-4o or Claude better for my task?", or "Does adding this sentence to my system prompt increase task accuracy?"
An experiment consists of several components:
- Dataset: The inputs to the AI application that we want to test.
- Task: The task executes the workflow that we are testing. An example task is to query GPT-4o-mini with a system and user prompt.
- Evaluators: The criteria that we are evaluating on, such as similarity to the gold label.
1. Install Patronus Module
You can use our python SDK to run batched evaluations and track experiments. If you prefer to run batched evaluations in a different language, follow our API reference guide.
pip install patronus
2. Set Environment Variables
If you do not have a Patronus AI API Key, see our quick start here for how to create one.
export PATRONUS_API_KEY=<YOUR_API_KEY>
3. Run an Experiment
Let's run a simple experiment that quizzes GPT-4o-mini on some science questions and checks if the output matches the correct answer.
import os
from patronus import Client, task, evaluator, Row, TaskResult
client = Client(
# This is the default and can be omitted
api_key=os.environ.get("PATRONUS_API_KEY"),
)
@task
def my_task(row: Row):
return f"{row.evaluated_model_input} World"
@evaluator
def exact_match(row: Row, task_result: TaskResult):
return task_result.evaluated_model_output == row.evaluated_model_gold_answer
client.experiment(
"Tutorial Project",
dataset=[
{
"evaluated_model_input": "Hello",
"evaluated_model_gold_answer": "Hello World",
},
],
task=my_task,
evaluators=[exact_match],
)
Here we have defined a few concepts
- A Dataset containing an array of inputs and gold answers that is used in our evaluation
- A Task representing our AI system
- A simple Evaluator that checks whether the output matches the gold answer
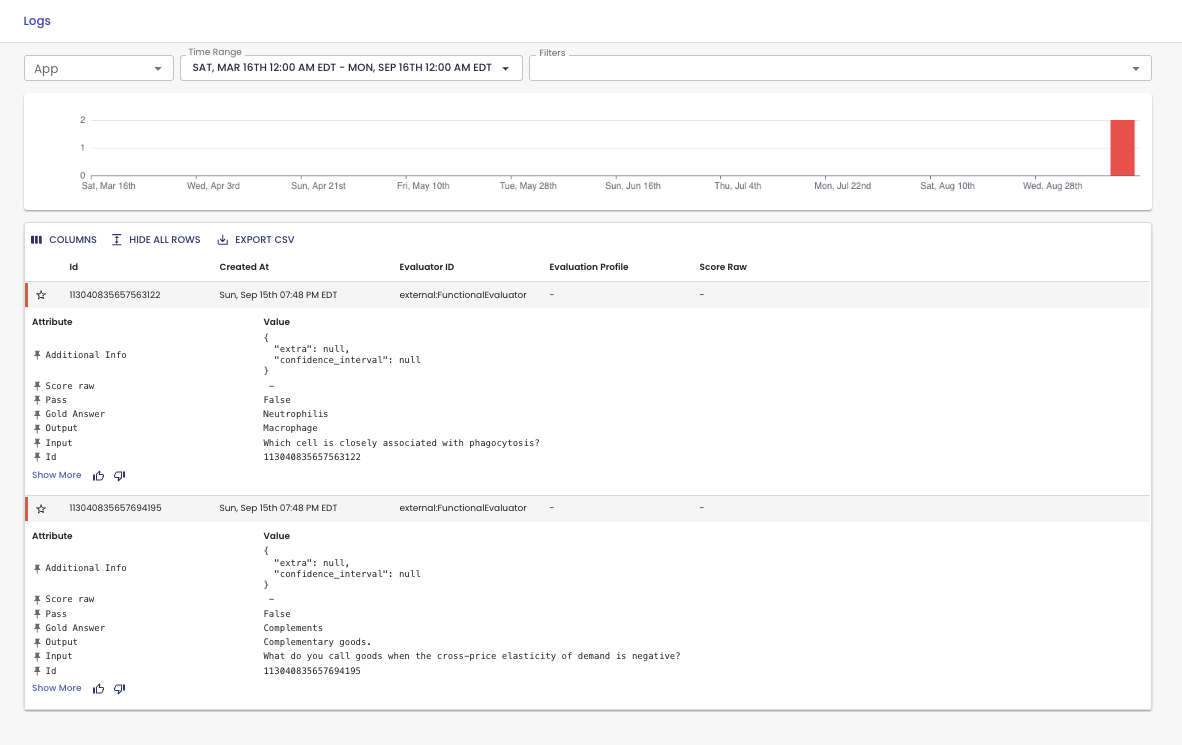
4. View Experiment Results
Your experiment run should've generated a link to the platform. You can view experiment results in the Logs UI.
Updated 1 day ago