
FinanceBench
LLMs applied in financial applications can produce incorrect responses, which pose significant risks for end users and downstream financial transactions. Due to the lack of real world grounded benchmarks in finance, it is difficult to measure and improve the performance of RAG systems applied to finance.
FinanceBench is a first-of-its-kind test suite for evaluating the performance of LLMs on open book financial question answering (QA). The full benchmark comprises 10,231 questions about publicly traded companies, with corresponding answers and evidence strings. The questions in FinanceBench are ecologically valid and cover a diverse set of scenarios.
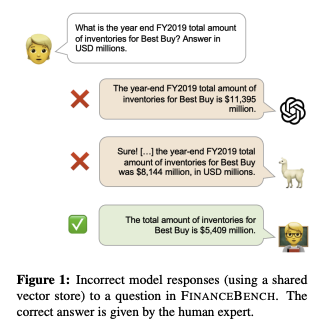
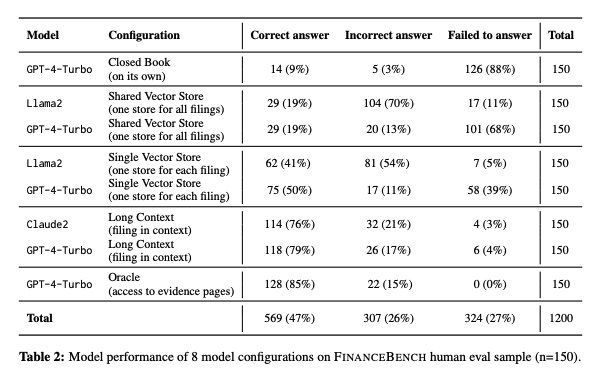
Our research team tested 16 state of the art model configurations (including GPT-4-Turbo, Llama2 and Claude2, with vector stores and long context prompts) on a sample of 150 cases from FinanceBench, and manually review their answers (n=2,400). The cases are available open-source. We show that existing LLMs have clear limitations for financial QA. Notably, GPT-4-Turbo used with a retrieval system incorrectly answered or refused to answer 81% of questions. While augmentation techniques such as using longer context window to feed in relevant evidence improve performance, they are unrealistic for enterprise settings due to increased latency and cannot support larger financial documents. We find that all models examined exhibit weaknesses, such as hallucinations, that limit their suitability for use by enterprises.
The open source subset of FinanceBench is supported in Patronus Datasets. To license the full FinanceBench benchmark, reach out to the Patronus AI team at [email protected].
Read the research: https://arxiv.org/abs/2311.11944
View the dataset in HuggingFace: https://huggingface.co/datasets/PatronusAI/financebench
Github Repository: https://github.com/patronus-ai/financebench
Updated 24 days ago