
Patronus Evaluators 🛡️
Overview
The Patronus Evaluation Suite is a large set of high quality, industry-leading Evaluators that provided automated evaluations for every possible AI application scenario.
Broadly speaking, evaluators fall into one of 3 categories: capabilities, safety or alignment.
- Capabilities: Capabilities evaluators measure the accuracy or capabilities of an AI system. This includes hallucination detection in a RAG system, measurements of context relevance for a retriever, or comparison to ground truth answers.
- Safety: Safety evaluators ensure that outputs do not violate industry safety requirements, including PII leakage, toxic content, biases against protected categories, prompt injections and more.
- Alignment: Alignment evaluators capture application specific requirements and open ended human preferences for AI behavior. This includes preferences for tone control, constraints on topics, or brand awareness such as avoiding references to competitors.
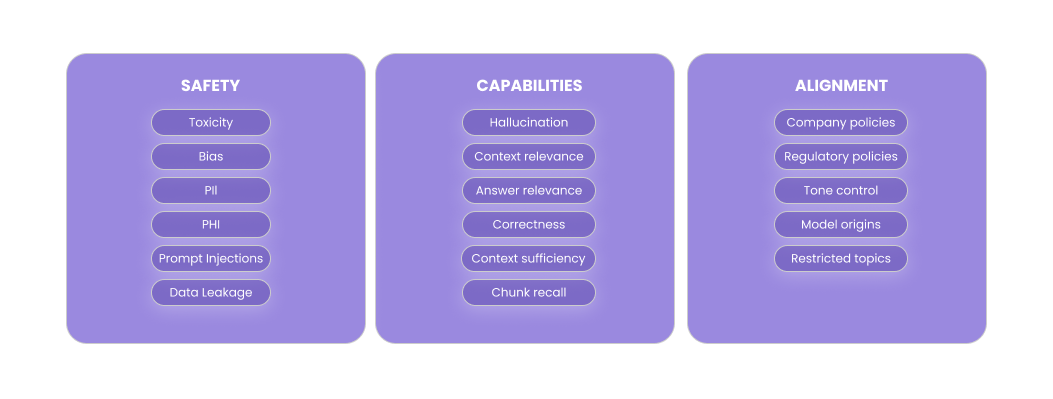
Each evaluator can be used in conjunction with a Dataset, or in isolation on arbitrary inputs and outputs.
In this guide you'll learn about the diversity of Patronus evaluators and how to use them to score AI outputs in any use case.
Topics covered
- Using Evaluators
- Evaluators Reference Guide
- Evaluator families and aliases
- Judge Evaluators
- Evaluators Examples
Updated 7 days ago