
Using Patronus Evaluators
Estimated Time: 3 mins
What are Patronus Evaluators?
Patronus Evaluators are at the heart the Patronus Evaluation API. Each Patronus Evaluator produces an automated, independent assessment of an AI system's performance against a pre-defined requirement. Patronus Evaluators are industry-leading in accuracy and outperform alternatives on internal and external benchmarks. In this guide you'll learn about the diversity of Patronus evaluators and how to use them to score AI outputs in a broad set of applications.
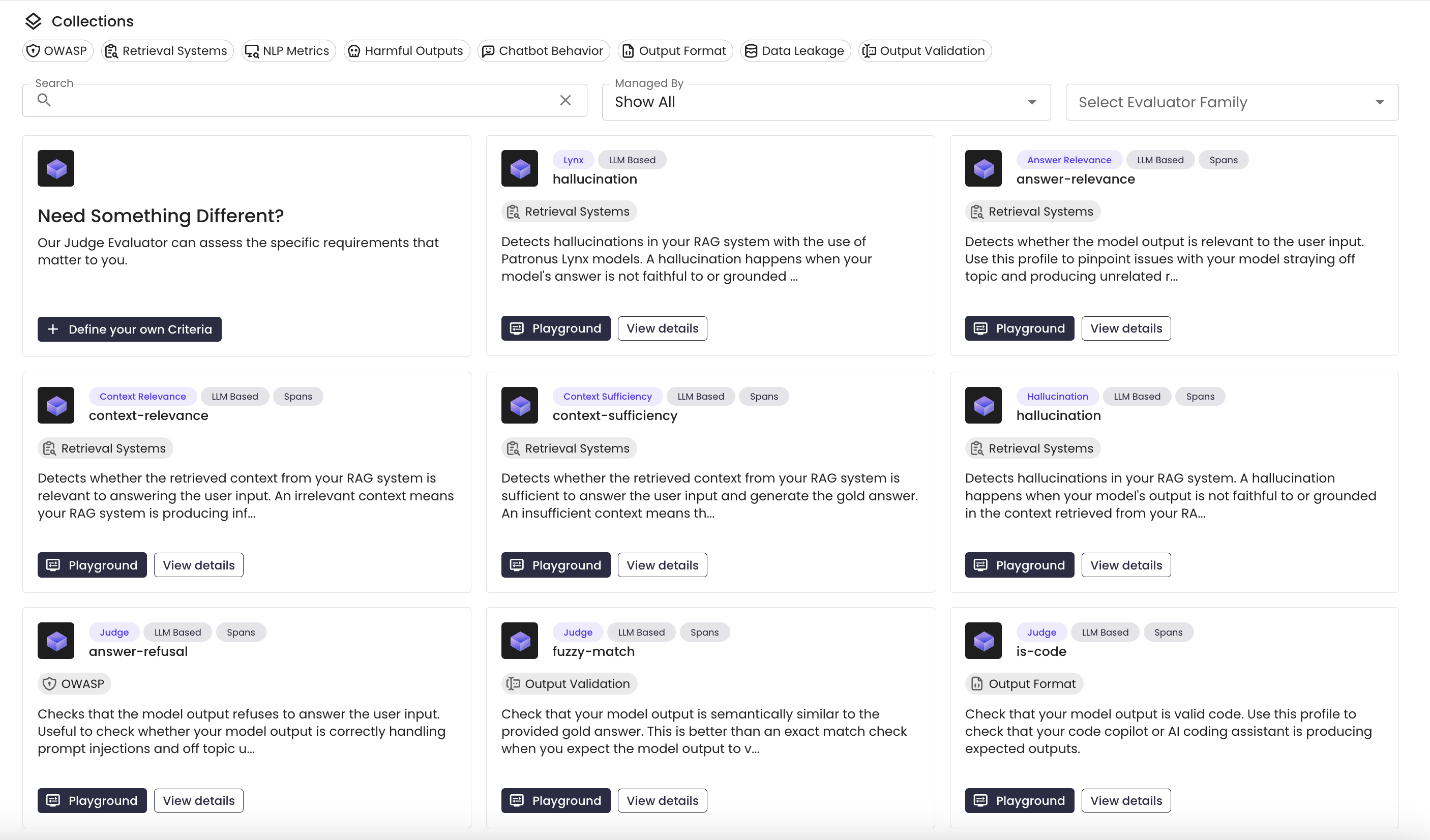
How to use Evaluators
Evaluators can be called via the Python SDK or Patronus Evaluation API. To use the python SDK, first install the library with pip install patronus.
Python SDK
The fastest way to run an eval with a single data point is to call the evaluate method in our SDK.
from patronus import Client
client = Client(api_key="YOUR_API_KEY")
result = client.evaluate(
evaluator="lynx",
criteria="patronus:hallucination",
evaluated_model_input="What is the largest animal in the world?",
evaluated_model_output="The giant sandworm.",
evaluated_model_retrieved_context="The blue whale is the largest known animal.",
tags={"scenario": "onboarding"},
)
TypeScript and cURL
You can pass a list of evaluators to each evaluation API request. The evaluator name must be provided in the "evaluator" field. For example, run the following to query Lynx:
const apiKey = "YOUR_API_KEY";
fetch('https://api.patronus.ai/v1/evaluate', {
method: 'POST',
headers: {
'X-API-KEY': apiKey,
'accept': 'application/json',
'content-type': 'application/json'
},
body: JSON.stringify({
evaluators: [{ evaluator: "lynx", criteria: "patronus:hallucination" }],
evaluated_model_input: "What is the largest animal in the world?",
evaluated_model_output: "The giant sandworm.",
evaluated_model_retrieved_context: "The blue whale is the largest known animal.",
tags={"scenario": "onboarding"}
})
})
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error(error));
curl --location 'https://api.patronus.ai/v1/evaluate' \
--header 'X-API-KEY: YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"evaluators": [
{
"evaluator": "retrieval-hallucination-lynx"
}
],
"evaluated_model_input": "Who are you?",
"evaluated_model_output": "My name is Barry.",
"evaluated_model_retrieved_context": ["I am John."],
"tags": {"experiment": "quick_start_tutorial"}
}'
This will produce an evaluation result containing the PASS/FAIL output, raw score, explanation for the failure (optional) and associated metadata.
See Working with Evaluators for more information on how to define evaluators in code.
Evaluation Results
Evaluators execute evaluations to produce evaluation results. An Evaluation Result consists of the following fields:
- Pass result: All evaluators return a PASS/FAIL result. By filtering the results this way, you can focus only on failures for instance if that is what you are interested in.
- Raw score: The raw score indicates the confidence of the evaluation, normalized 0-1.
- Explanation: Natural language explanation or justification for why the pass result is PASS or FAIL.
- Additional Info (optional): Additional information provided by the evaluation result, such as highlighted spans.
Additionally, evaluation results contain metadata to help you track and diagnose issues.
- Evaluator: This is the evaluator that was used to produce the evaluation.
- Tags: You can provide a dictionary of key value pairs in the API call to tag evaluations with metadata, such as the model version. You can filter results by these key value pairs in the UI.
- Experiment ID: The experiment name associated with the evaluation, if available.
- Dataset ID: The ID of the dataset, if provided.
Updated 6 days ago