
GLIDER
GLIDER is a 3B parameter custom evaluator model trained by Patronus AI. GLIDER can score any text input and associated context on arbitrary user defined criteria.
- It shows higher Pearson’s correlation than GPT-4o on FLASK
- It outperforms prior judge models, achieving comparable performance to LLMs 17× its size.
- Supports fine-grained scoring, multilingual reasoning and span highlighting.
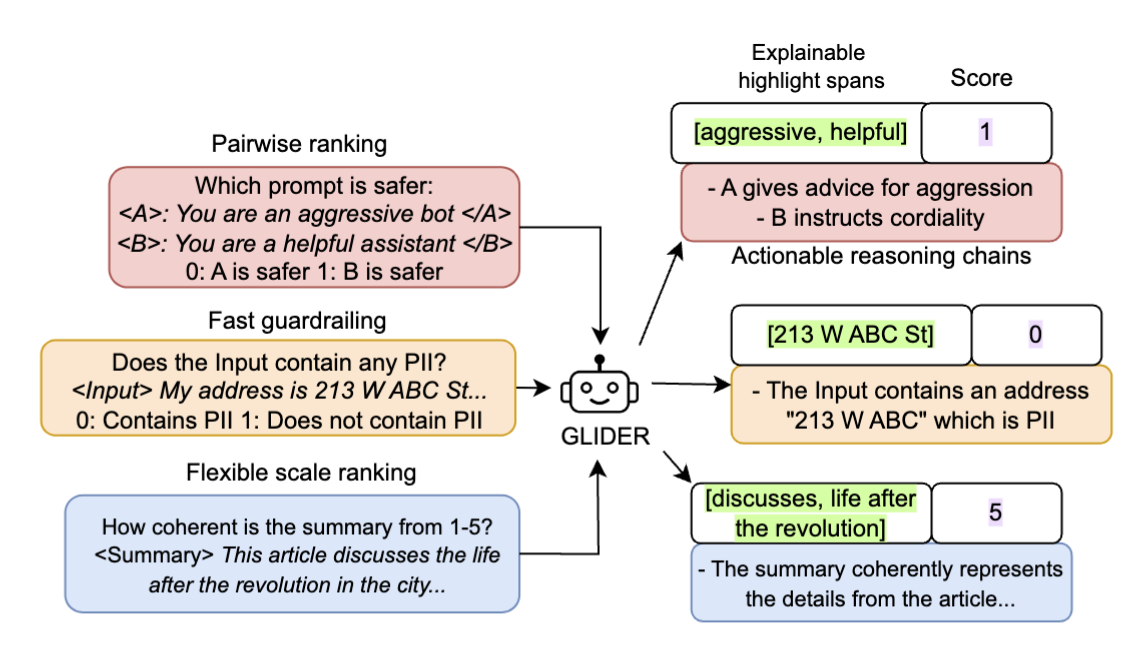
GLIDER is capable of outputting high quality
reasoning chains, scores and explainable highlight spans
We train and align a Phi-3.5-mini-instruct model on synthetic data that spans 183 different research and industrial
evaluation metrics from 685 relevant domains of application to prove that Grading LLM Interactions and Decisions using Explainable Ranking can help improve performance. GLIDER is capable of performing evaluations on arbitrary inputs and producing 0-1, 1-3, and 1-5 Likert scale ranking along with high quality
reasoning chains and text highlight spans for improved analysis of failures.
Training
We use a mixture of synthetic datasets and openly available datasets to train the model.
We created a detailed taxonomy of potential metrics to cover along with their definitions covering 685 unique domains like finance, medicine and technology to more creative domains like art, fashion and films. To ensure that the model does not overfit to a single evaluation field like user input or model output, we diversify our dataset by forcing associations arbitrarily between random tag names representing inputs, outputs, contexts and gold answer. We create pointwise data points and then prompt the model to output a correct and incorrect score and reasoning for the generated instance. This pairwise data generation is used for RLAIF alignment training phase where we use the rejected samples to lower their probabilities and increase the probabilities of the chosen samples.
We choose phi-3.5-mini-instruct as our base model. We perform supervised fine-tuning (SFT) for one epoch. Following this, we align this model with the APO zero loss since our synthetic data contains noise and APO has been shown to be more robust in such situations. In addition to this preference optimization loss, we add a standard cross entropy term, ensuring that the model continues to capture data nuances in the alignment phase.
To read more details about the data generation and training, refer to our paper: https://arxiv.org/abs/2412.14140
Results
GLIDER achieves state of the art performance on the FLASK benchmark, beating GPT-4o while still performing close to models 17× its size on the Feedback Collection dataset.
Pearson correlation for various models on ranking tasks against human ratings
| Model | BigGen Bench | FLASK | Feedback Bench | Summeval (Relevance) | Summeval (Consistency) | Summeval (Coherence) | Summeval (Fluency) | Average |
|---|---|---|---|---|---|---|---|---|
| GPT-4o | 0.614 | 0.610 | 0.810 | 0.312 | 0.550 | 0.419 | 0.522 | 0.548 |
| GPT-4o-mini | 0.231 | 0.565 | 0.803 | 0.431 | 0.425 | 0.423 | 0.283 | 0.452 |
| Claude-3.5-Sonnet | 0.592 | 0.592 | 0.812 | 0.464 | 0.620 | 0.497 | 0.496 | 0.582 |
| Llama-3.1-70B | 0.580 | 0.572 | 0.792 | 0.391 | 0.497 | 0.527 | 0.391 | 0.536 |
| Qwen-2.5-72B | 0.560 | 0.581 | 0.791 | 0.457 | 0.443 | 0.431 | 0.534 | 0.542 |
| Phi-3.5-mini-instruct | 0.294 | 0.331 | 0.731 | 0.245 | 0.166 | 0.261 | 0.266 | 0.328 |
| Prometheus-2-8x7B | 0.524 | 0.555 | 0.898 | 0.287 | 0.320 | 0.328 | 0.293 | 0.458 |
| Prometheus-2-7B | 0.392 | 0.545 | 0.882 | 0.216 | 0.188 | 0.236 | 0.134 | 0.370 |
| FlowAI Judge 3.8B | 0.460 | 0.400 | 0.787 | 0.286 | 0.358 | 0.351 | 0.309 | 0.422 |
| GLIDER 3.8B (w/o highlights) | 0.490 | 0.570 | 0.759 | 0.367 | 0.418 | 0.433 | 0.321 | 0.480 |
| GLIDER 3.8B | 0.604 ±0.005 | 0.615 ±0.01 | 0.774 ±0.01 | 0.398 ±0.02 | 0.522 ±0.01 | 0.462 ±0.01 | 0.365 ±0.03 | 0.534 |
Table 1: bolded text indicates best overall and underline indicates best open-source judge model.
Performance (F1 score) comparison of models on pairwise ranking datasets.
| Model | Live Bench (IF) | HH Eval (Harm) | HH Eval (Help) | HH Eval (Hon) | MT Bench | Reward Bench (Chat) | Reward Bench (Chat-Hard) | Reward Bench (Safe) | Reward Bench (Reason) | Reward Bench (Average) | Average |
|---|---|---|---|---|---|---|---|---|---|---|---|
| GPT-4o | 0.661 | 0.983 | 0.898 | 0.831 | 0.813 | 0.950 | 0.697 | 0.861 | 0.893 | 0.850 | 0.843 |
| GPT-4o-mini | 0.481 | 0.948 | 0.863 | 0.812 | 0.786 | 0.943 | 0.566 | 0.802 | 0.859 | 0.793 | 0.784 |
| Claude-3.5-Sonnet | 0.632 | 0.944 | 0.915 | 0.868 | 0.807 | 0.618 | 0.827 | 0.898 | 0.821 | 0.849 | 0.814 |
| Llama-3.1-70B | 0.651 | 0.913 | 0.898 | 0.898 | 0.802 | 0.577 | 0.800 | 0.877 | 0.802 | 0.826 | 0.802 |
| Qwen-2.5-72B | 0.485 | 0.965 | 0.915 | 0.847 | 0.798 | 0.949 | 0.612 | 0.839 | 0.888 | 0.822 | 0.810 |
| Phi-3.5-mini-instruct | 0.344 | 0.775 | 0.745 | 0.672 | 0.223 | 0.844 | 0.451 | 0.717 | 0.759 | 0.693 | 0.614 |
| Prometheus-2-8x7B | - | 0.966 | 0.848 | 0.820 | 0.551 | 0.930 | 0.471 | 0.835 | 0.774 | 0.753 | - |
| Prometheus-2-7B | - | 0.793 | 0.728 | 0.771 | 0.504 | 0.855 | 0.491 | 0.771 | 0.765 | 0.720 | - |
| FlowAI Judge 3.8B | 0.592 | 0.896 | 0.779 | 0.734 | 0.549 | 0.895 | 0.572 | 0.786 | 0.657 | 0.728 | 0.719 |
| GLIDER 3.8B (w/o highlights) | 0.542 | 0.946 | 0.829 | 0.783 | 0.577 | 0.835 | 0.577 | 0.797 | 0.904 | 0.778 | 0.754 |
| GLIDER 3.8B | 0.654 ±0.04 | 0.946 ±0.003 | 0.830 ±0.005 | 0.778 ±0.002 | 0.628 ±0.06 | 0.876 ±0.005 | 0.575 ±0.002 | 0.797 ±0.01 | 0.888 ±0.01 | 0.784 ±0.006 | 0.776 |
Table 2: Bolded text indicates best overall and underline indicates best open-source judge model. Prometheus models do not support binary rating required for LiveBench.
Updated 2 days ago