
Agent Observability
Agent observability in Patronus is the real time monitoring and evaluation of end-to-end agent executions. Embedding observability and evaluation in agent executions is important, because it can identify failures such as
- Incorrect tool use
- Failure to delegate a task
- Unsatisfactory answers
- Incorrect tool outputs
Observing and evaluating agents in Patronus is the process of embedding evaluators in agent executions so that agent behaviors can be continuously monitored and analyzed in the platform.
Embedding Evaluators in Agents
The first step in evaluating an agent is to define a set of evaluators. See the Evaluators section to understand the difference between class based and Patronus API evaluators.
Let's create an example coding agent using CrewAI. The agent calls a LLM API and retrieves a response (example uses OpenAI, but any LLM API is equivalent).
from crewai_tools import BaseTool
from openai import OpenAI
class APICallTool(BaseTool):
name: str = "OpenAI Tool"
description: str = (
"This tool calls the LLM API with a prompt and an optional system prompt. This function returns the response from the API."
)
client: ClassVar = OpenAI()
def _run(self, system_prompt: str=None, prompt: str=None) -> str:
response = self.client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": system_prompt
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt,
}
]
}
],
max_tokens=4095,
temperature=1,
top_p=1,
response_format={
"type": "text"
},
)
return response.choices[0].message.content
Suppose we want to evaluate the helpfulness of the agent response. To embed a Patronus evaluator, simply add the following:
from patronus import Client
client = Client(api_key="<PROVIDE YOUR API KEY>")
result = client.evaluate(
evaluator="judge",
criteria="patronus:is-conscise",
evaluated_model_output="<YOUR AGENT RESPONSE>",
)
We can embed this evaluator in the tool call, right after the generation:
from crewai_tools import BaseTool
from openai import OpenAI
from typing import ClassVar
from patronus import Client
class APICallTool(BaseTool):
name: str = "OpenAI Tool"
description: str = (
"This tool calls the LLM API with a prompt and an optional system prompt. This function returns the response from the API."
)
client: ClassVar = OpenAI()
patronus_client: ClassVar = Client(api_key="<PROVIDE YOUR API KEY>")
def _run(self, system_prompt: str=None, prompt: str=None) -> str:
response = self.client.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "system",
"content": [
{
"type": "text",
"text": system_prompt
}
]
},
{
"role": "user",
"content": [
{
"type": "text",
"text": prompt,
}
]
}
],
max_tokens=4095,
temperature=1,
top_p=1,
response_format={
"type": "text"
},
)
llm_output = response.choices[0].message.content
result = client.evaluate(
evaluator="judge",
criteria="patronus:is-concise",
evaluated_model_output=llm_output,
)
Now you can run the agent with crewai run, and you will see evaluation results populated in real time in Logs.
That's it! Now each agent execution that is triggered will also log outputs and evals to the Patronus logs dashboard.
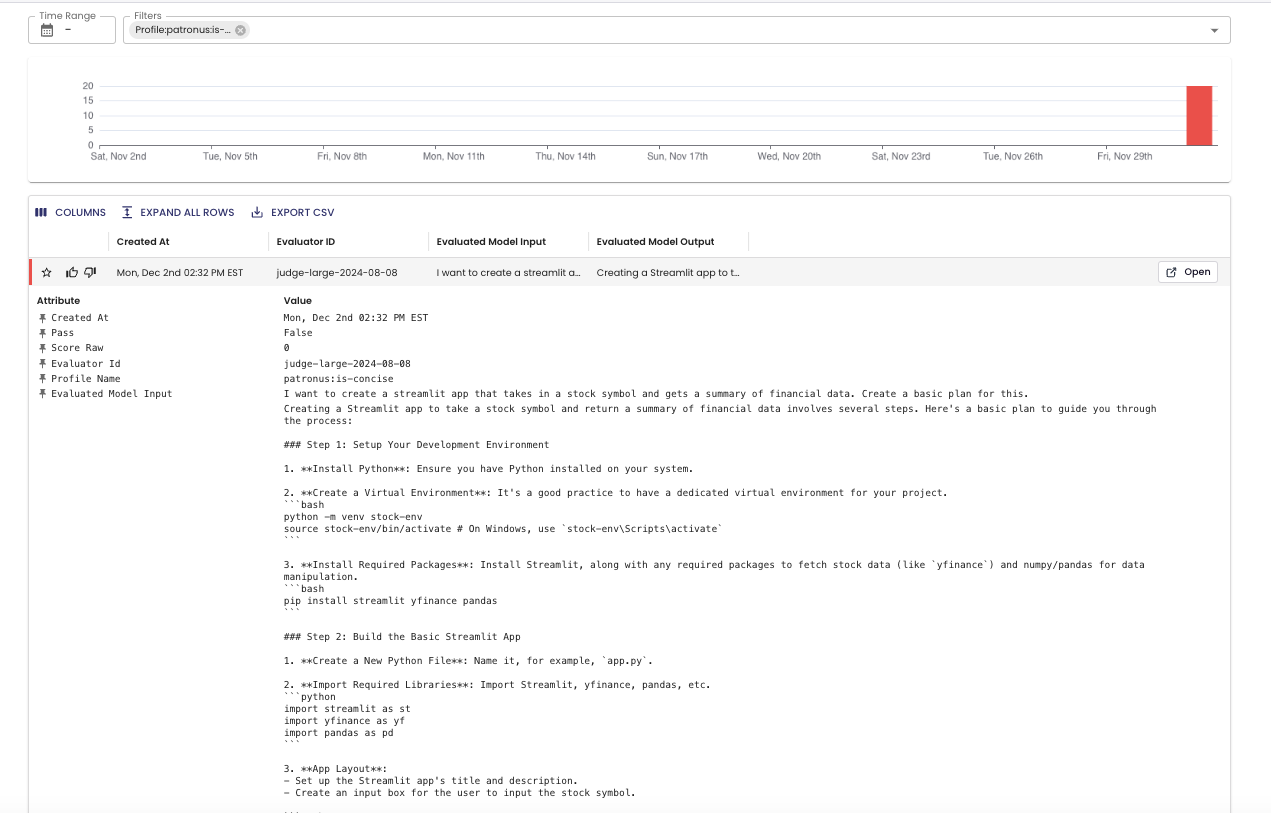
Embedding evaluators in agent executions enables agent behaviors to be continuously monitored and analyzed our the platform. You can send alerts on failed agent outputs, filter for interesting examples and add it to your testing data, and re-try the agent response when there are failures. The possibilities are endless! 🌈
Updated 19 days ago