
Log an Eval
Logging an eval is very simple and can be achieved in < 5 minutes. If you do not have an API key, sign up for an account at app.patronus.ai. To create an API key, click on API Keys.
Logging Evals (SDK and API)
You can log evals via the Python SDK or API. To log evals with client.evaluate(...) in the Python SDK, first install the library with pip install patronus.
Logging expects the following params:
evaluatorcriteriaevaluated_model_inputevaluated_model_outputevaluated_model_retrieved_contexttags
Simply run the following code by replacing YOUR_API_KEY with the API Key you just created.
from patronus import Client
client = Client(api_key="YOUR_API_KEY")
result = client.evaluate(
evaluator="lynx-small",
criteria="patronus:hallucination",
evaluated_model_input="What is the largest animal in the world?",
evaluated_model_output="The giant sandworm.",
evaluated_model_retrieved_context="The blue whale is the largest known animal.",
tags={"scenario": "onboarding"},
)
const apiKey = "YOUR_API_KEY";
fetch('https://api.patronus.ai/v1/evaluate', {
method: 'POST',
headers: {
'X-API-KEY': apiKey,
'accept': 'application/json',
'content-type': 'application/json'
},
body: JSON.stringify({
evaluators: [{ evaluator: "lynx", criteria: "patronus:hallucination" }],
evaluated_model_input: "What is the largest animal in the world?",
evaluated_model_output: "The giant sandworm.",
evaluated_model_retrieved_context: "The blue whale is the largest known animal.",
tags={"scenario": "onboarding"}
})
})
.then(response => response.json())
.then(data => console.log(data))
.catch(error => console.error(error));
curl --location 'https://api.patronus.ai/v1/evaluate' \
--header 'X-API-KEY: YOUR_API_KEY' \
--header 'Content-Type: application/json' \
--data '{
"evaluators": [
{
"evaluator": "retrieval-hallucination-lynx",
"explain_strategy": "always"
}
],
"evaluated_model_input": "What is the largest animal in the world?",
"evaluated_model_output": "The giant sandworm.",
"evaluated_model_retrieved_context": ["The blue whale is the largest known animal."],
"tags": {"scenario": "onboarding"}
}'
In the above example, we are evaluating whether the output contains a hallucination using Lynx. The evaluation result is then automatically logged to the Logs dashboard.
View Logs in UI 📈
Now head to https://app.patronus.ai/logs. You can now view results for your most recent evaluation!
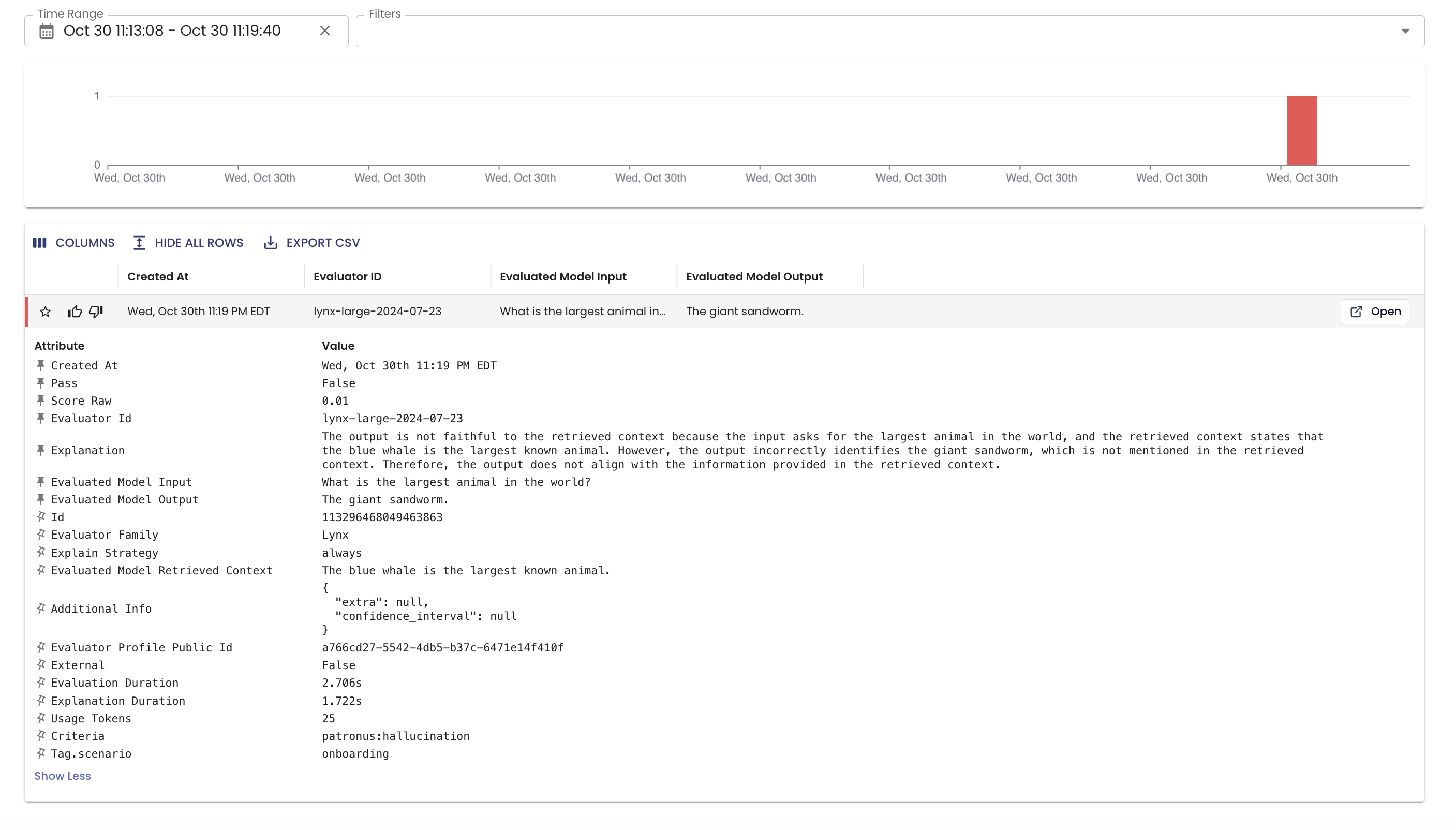
Evaluation Results consist of the following fields:
- Result: PASS/FAIL result for whether the LLM passed or failed the test
- Score: This is a score between 0 and 1 measuring confidence in the result
- Explanation: Natural language explanation for why the result and score was computed
In this case, Lynx scored the evaluation as FAIL because the context states that the largest animal is the blue whale, not the giant sandworm. We just flagged our first hallucination!
Now that you've logged your first evaluation, you can explore additional API fields, define your own evaluator, or run a batched evaluation experiment.
Updated 3 days ago