
Patronus Evaluators
Patronus Evaluators are powerful pre-built evaluators that run on Patronus infrastructure. Each Patronus Evaluator produces an automated, independent assessment of an AI system's performance against a pre-defined requirement. Patronus Evaluators are industry-leading in accuracy and outperform alternatives on internal and external benchmarks.
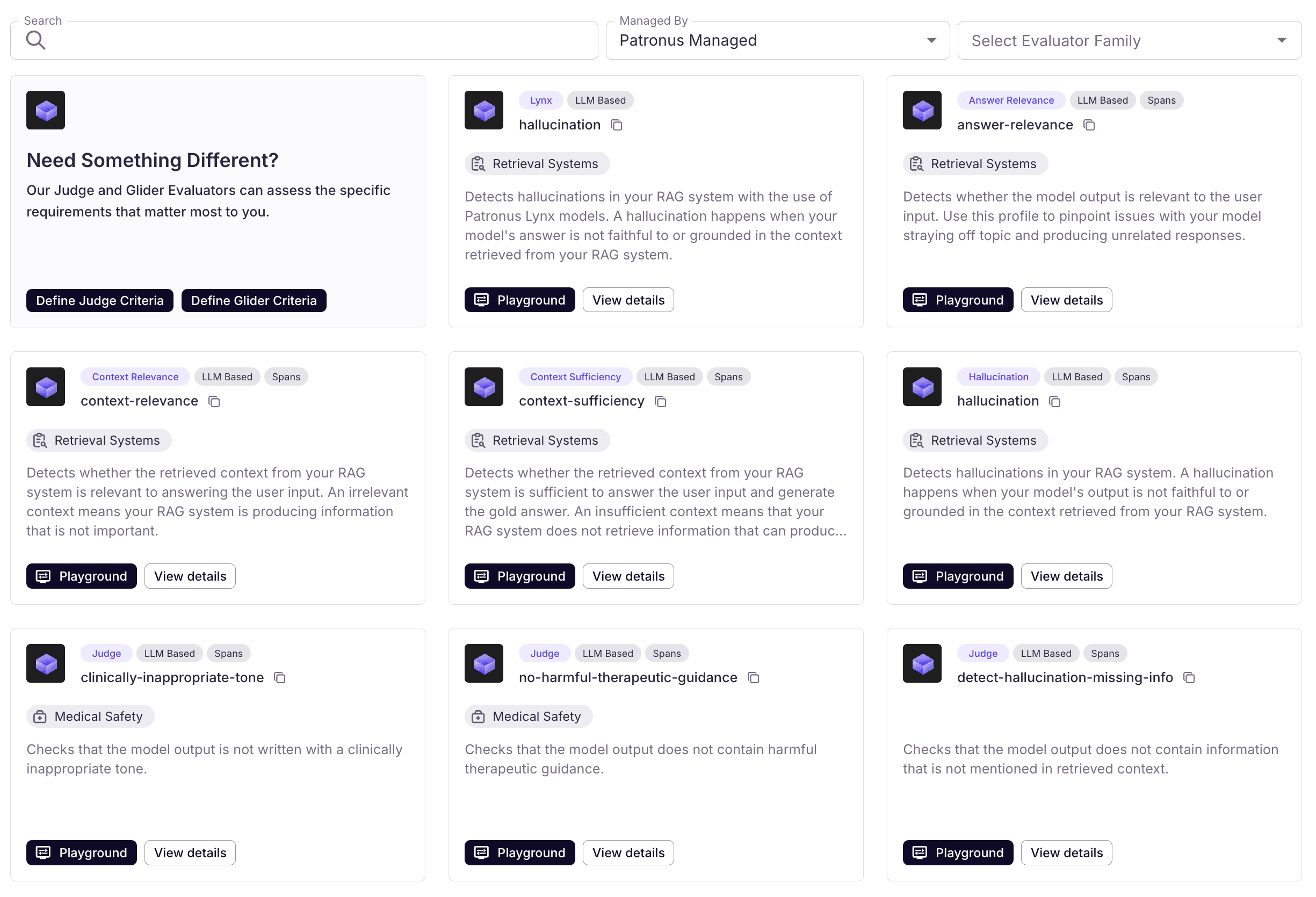
How to use Patronus Evaluators
Patronus evaluators can be called via the Python SDK or Patronus API. To use the Python SDK, first install the library with pip install patronus.
Using RemoteEvaluator (SDK)
The easiest way to use Patronus evaluators in the SDK is through the RemoteEvaluator class:
Using the Evaluation API
You can call Patronus evaluators directly via the REST API using Python, TypeScript, or cURL:
This will produce an evaluation result containing the PASS/FAIL output, raw score, explanation (optional), and associated metadata.
Controlling Explanations
Explanations are justifications attached to evaluation results, typically generated by an LLM. Patronus evaluators support explanations by default, with options to control when they're generated.
The explain_strategy parameter controls when explanations are generated:
"never": No explanations are generated for any evaluation results"on-fail": Only generates explanations for failed evaluations"on-success": Only generates explanations for passed evaluations"always"(default): Generates explanations for all evaluations
Performance Note: For optimizing latency in production environments, it's recommended to use either explain_strategy="never" or explain_strategy="on-fail" to reduce the number of generated explanations.
See Explanations for more details.
Using in Experiments
Remote evaluators integrate seamlessly with Patronus experiments:
Using with Tracing
Remote evaluators integrate seamlessly with Patronus tracing:
Evaluation Results
Evaluators execute evaluations to produce evaluation results. An Evaluation Result consists of the following fields:
- Pass result: All evaluators return a PASS/FAIL result. By filtering the results this way, you can focus only on failures for instance if that is what you are interested in.
- Raw score: The raw score indicates the confidence of the evaluation, normalized 0-1.
- Explanation: Natural language explanation or justification for why the pass result is PASS or FAIL.
- Additional Info (optional): Additional information provided by the evaluation result, such as highlighted spans.
Additionally, evaluation results contain metadata to help you track and diagnose issues.
- Evaluator: This is the evaluator that was used to produce the evaluation.
- Tags: You can provide a dictionary of key value pairs in the API call to tag evaluations with metadata, such as the model version. You can filter results by these key value pairs in the UI.
- Experiment ID: The experiment name associated with the evaluation, if available.
- Dataset ID: The ID of the dataset, if provided.