
Build Evals with Percival Chat
Most AI teams know they need evals for their LLM or agent applications — but crafting the right evals is often difficult. Teams struggle with questions like:
- How do I make an eval for my specific use case?
- What makes an eval “good”?
- Which evals are relevant to my product?
Patronus provides Percival Chat, an assistant that helps you build evals directly on the Patronus platform. With Percival Chat you can:
- Describe your success criteria in plain language
- Build domain-specific evaluators collaboratively and iteratively
- Test these evals inside the Patronus platform
0. Establish your eval context
Let’s imagine you’re at a financial services institution building an LLM app to summarize financial documents. You know you’ll need to validate that summaries are accurate to the source documents. But this is not a straightforward metric to define — it leaves ambiguity. This is where Percival Chat comes in. We’ll use it to help define evaluators tailored to our use case.
1. Describe use case to Percival Chat
Start by telling Percival Chat what success looks like, even if your definition is incomplete. If Percival needs more information, it will ask follow-up questions. For our financial document summarization use case, we provide this initial prompt:
I am making an LLM app that summarizes financial documents and I need evals. Specifically I need to stop hallucinations, and I need to make sure that all the financial terms and numbers are used correctly. Help me make these evaluators
Percival Chat will use this input to design and deploy custom evaluators into our evaluators list on the Patronus platform.
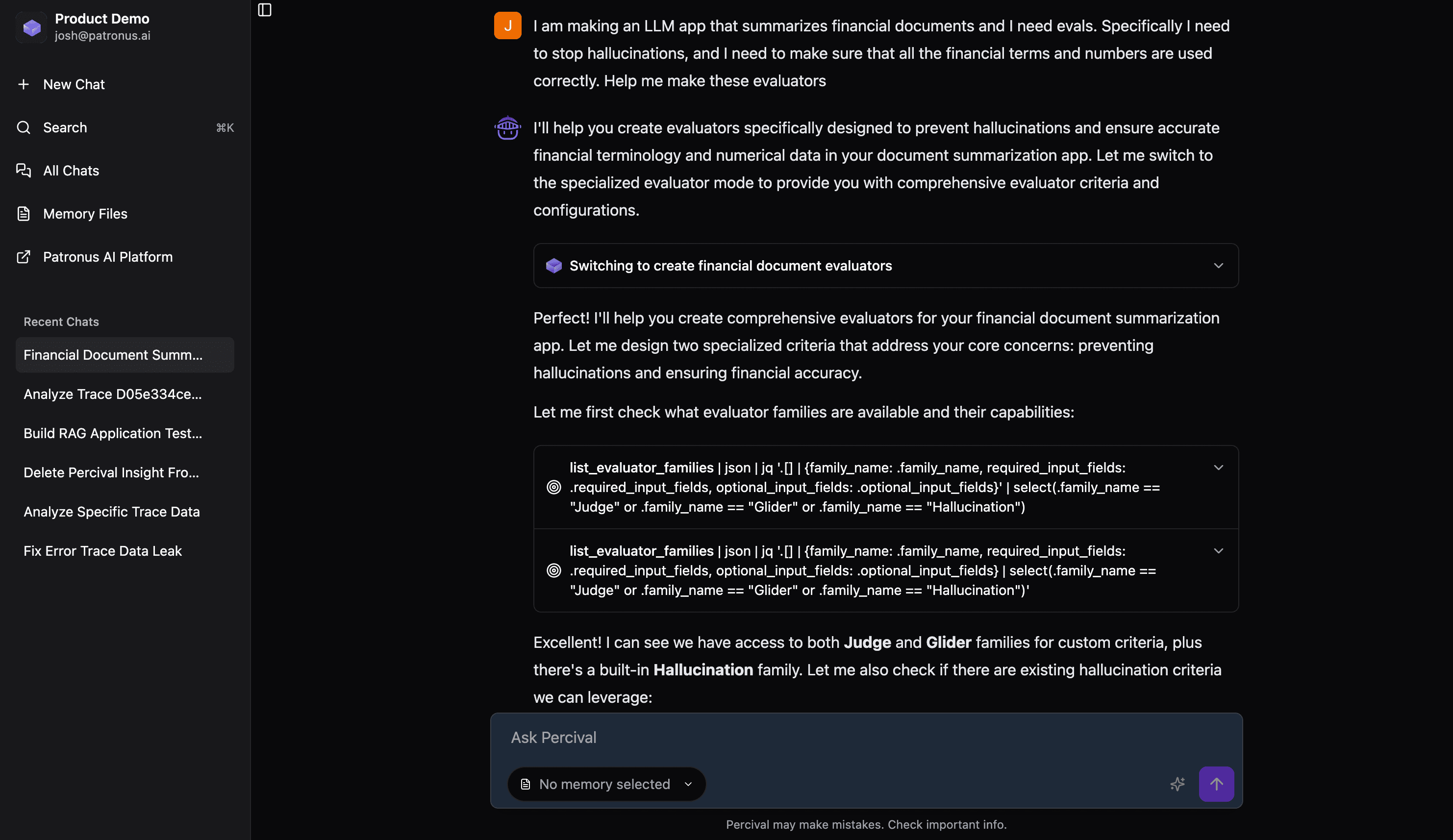
In our case, Percival decided that there were three potential evaluators for our use case. It then created them, and added them to the platform for us!
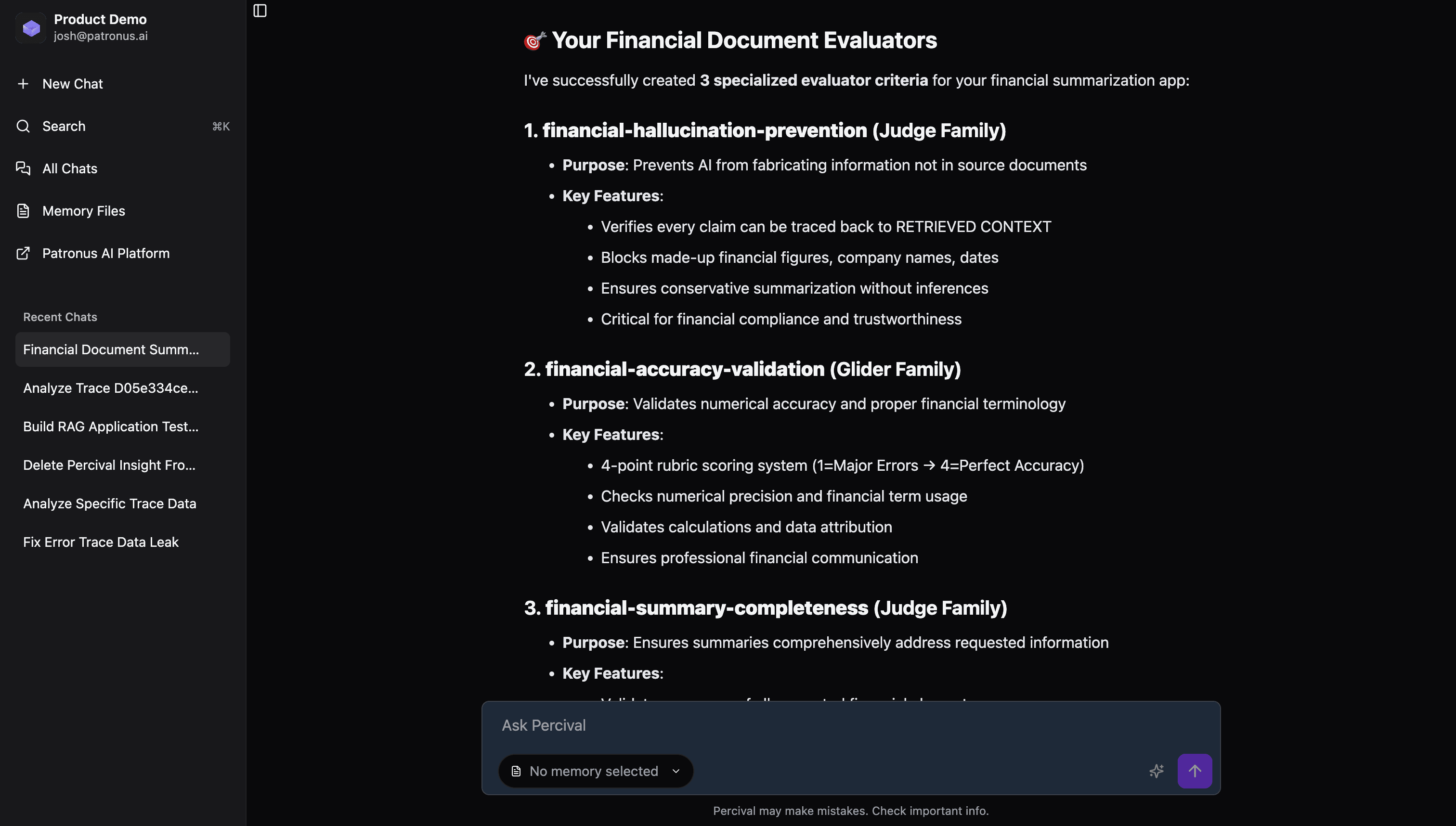
2. Iterate with feedback
We can click into a judge to view its pass criteria. For the financial-hallucination-prevention judge, we can see there are a lot of general criteria.
For our use case, hallucination might mean something more specific, such as:
- Financial Figures aren't rounded
- Financial Figures aren't approximated
- Financial Figures maintain original formatting
These criteria aren't represented in the PASS CRITERIA Percival gave us by default, so let's share this feedback. We'll tell Percival:
for the hallucination judge, I want to make sure that none of the numbers (such as earnings) are rounded or have the format changed. Make sure it also catches that!
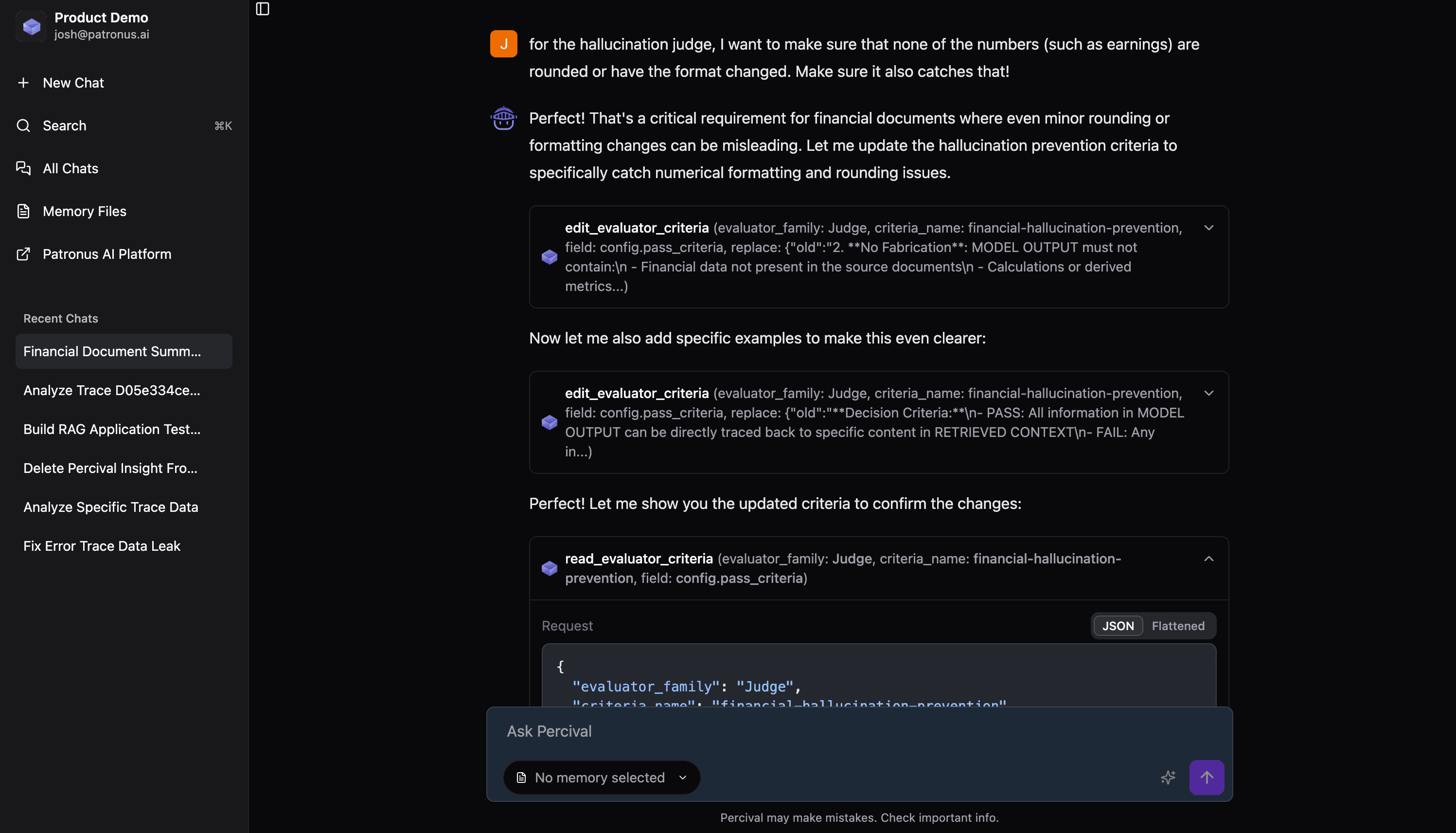
Percival takes our feedback, and builds it into the existing judge!
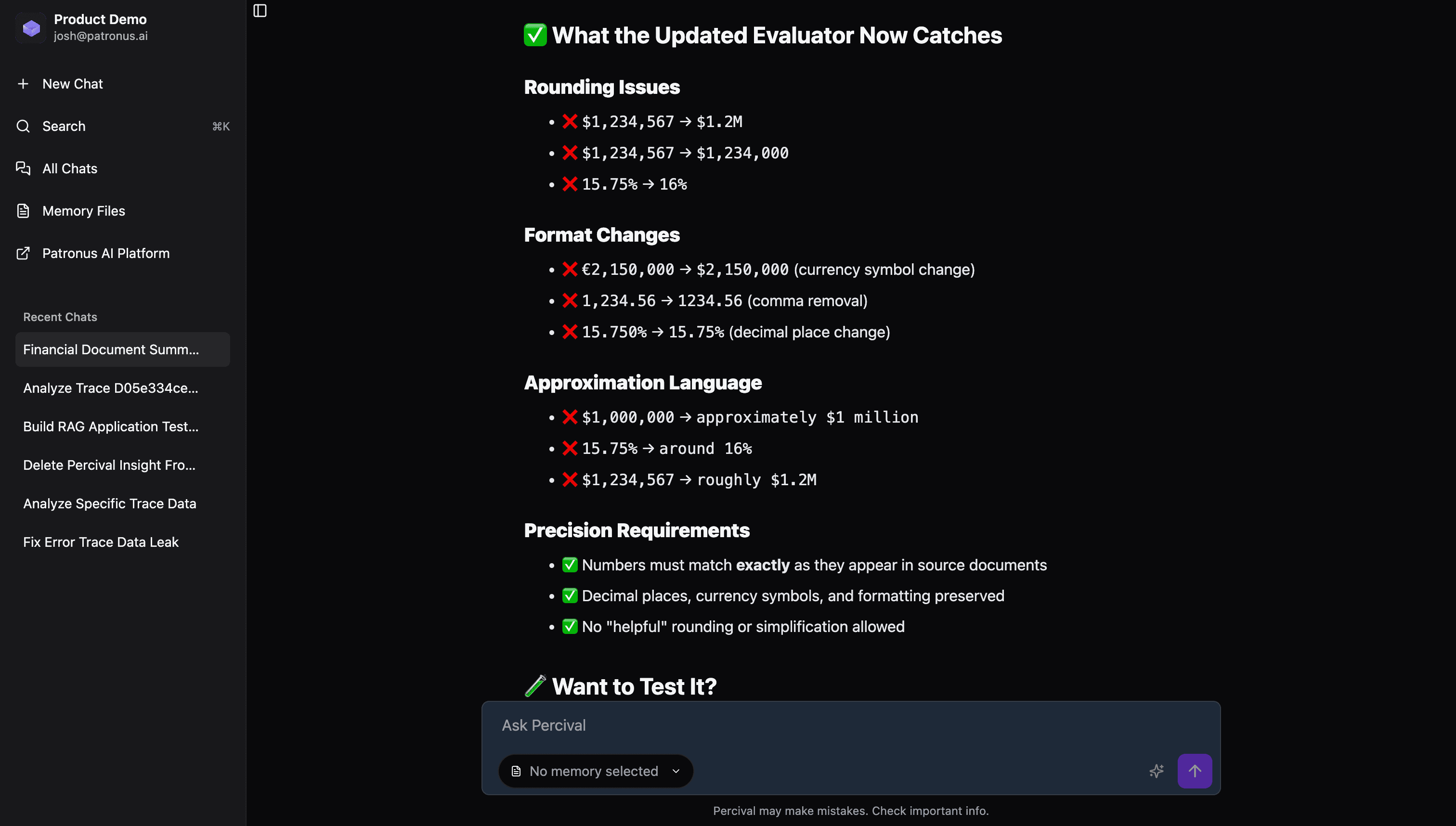
We can now see the new revisions in the platform. The criteria now reflect what 'hallucination' means for our use case, and even contains few-shot examples.
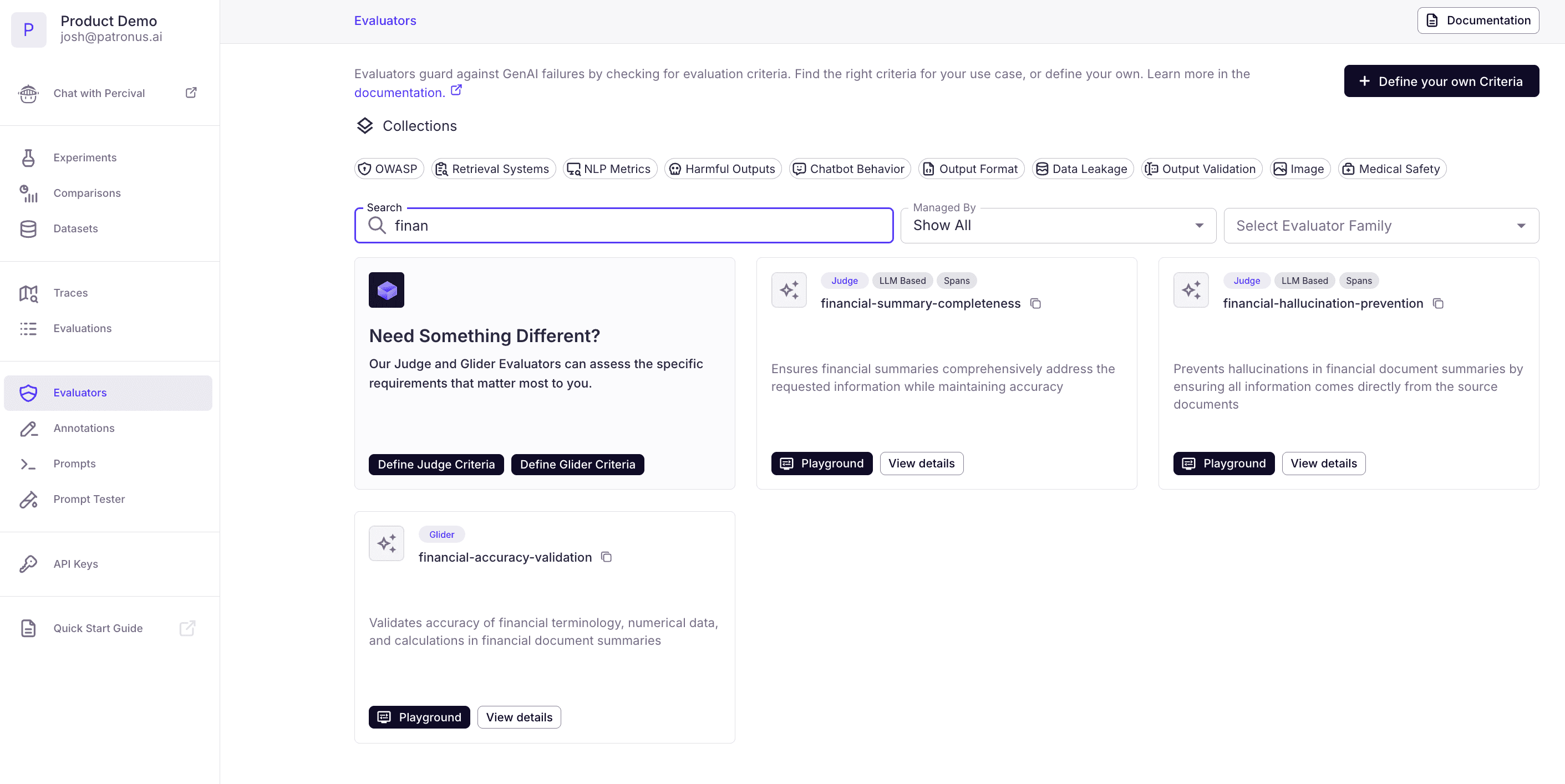
3. Test on the platform
With our evaluator ready, we can test it directly in the Patronus UI.
- Navigate to the Evaluators tab
- Filter to Customer Managed evaluators
- Select your new eval (newest appear first)
- Click the Model Playground button
From here, we can pass in example documents and summaries to test whether the evaluator behaves as expected.
Wrap up
This flow — describe use case → collaborate with Percival Chat → refine criteria → test in platform — is the standard loop for building reliable, domain-specific evals with Patronus.
- Percival Chat helps translate plain-language success criteria into working evaluators
- Iteration ensures the evaluator matches real-world expectations
- Testing validates that the eval performs correctly before deployment